Ricerca Vettoriale con Azure AI Search
-
Denis Dal Molin
- 28 Oct, 2025
- 11 Mins read
Introduzione
L’intelligenza artificiale è ormai una presenza discreta ma costante nella nostra vita quotidiana. Dalla ricerca vocale sui nostri smartphone ai sistemi di raccomandazione di Netflix o Spotify, l'IA è dappertutto, anche se spesso non la vediamo.
L’idea comune tende a concentrarsi su chatbot e assistenti virtuali, strumenti che ci permettono di interagire con la tecnologia tramite il linguaggio naturale. Tuttavia, questo rappresenta solo uno degli usi, e in un certo senso, il più "superficiale". Oggi, le sue applicazioni si estendono a settori complessi come la medicina, la finanza, l'automazione industriale e la logistica. Qui, l’IA non si limita a rispondere a domande, ma viene utilizzata per analizzare enormi quantità di dati, prendere decisioni in tempo reale e ottimizzare processi aziendali in modo da massimizzare l'efficienza.
In un contesto come quello odierno, dove i dati sono diventati la risorsa più preziosa, la capacità di un sistema di comprendere e analizzare informazioni anche non strutturate è fondamentale per estrarre valore utile.
Gli algoritmi di machine learning vengono impiegati per ottimizzare processi decisionali che vanno dalla previsione della domanda di mercato alla gestione del magazzino, passando per la personalizzazione dei prodotti e l’analisi delle tendenze emergenti.
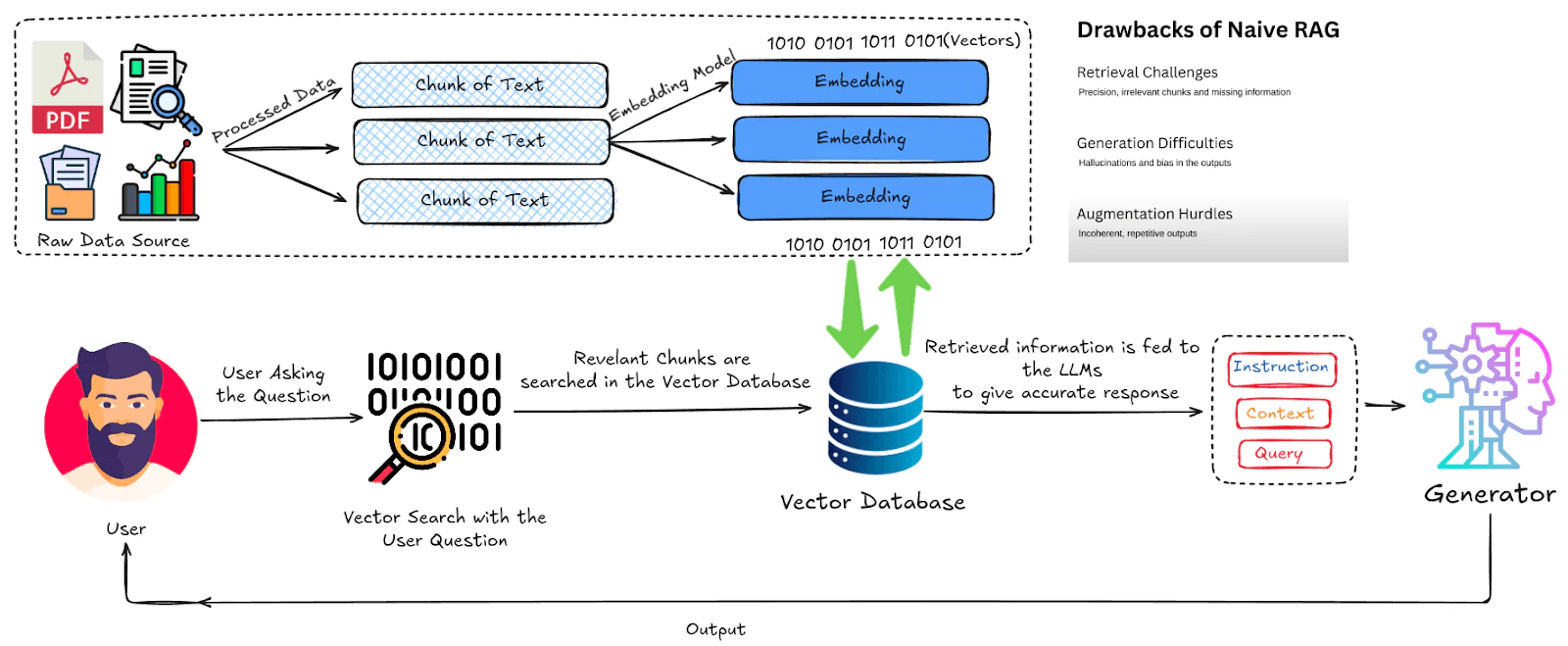
In quest’ottica, un concetto sempre più rilevante è la capacità dell'IA di effettuare ricerche avanzate e intelligenti, non più limitate alla mera corrispondenza tra parole chiave, ma in grado di cogliere il significato e la semantica dei contenuti.
La retrieval-augmented generation (RAG) è un ottimo esempio di questa evoluzione, dove l’IA non solo ricerca informazioni rilevanti, ma le utilizza attivamente per generare risposte personalizzate e coerenti.
Il problema delle Keyword
Fino a qualche anno fa, la ricerca online si basava quasi esclusivamente su un sistema di parole chiave, un metodo che tuttavia presenta diversi limiti. Se un contenuto è troppo ampio o complesso, trovare la subito risposta giusta tra i risultati non è scontato.
Le persone fanno domande, utilizzano sinonimi, combinano concetti in modi variabili. La ricerca tradizionale non riesce a comprendere questi aspetti più dinamici del linguaggio umano.
Servono strumenti che confrontino concetti, non stringhe, estraendo il contenuto veramente rilevante anche quando le parole usate sono diverse, ma il significato è lo stesso.
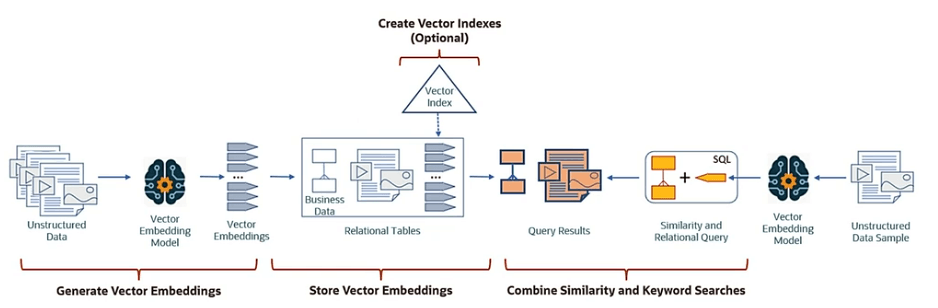
Gli Indici Vettoriali
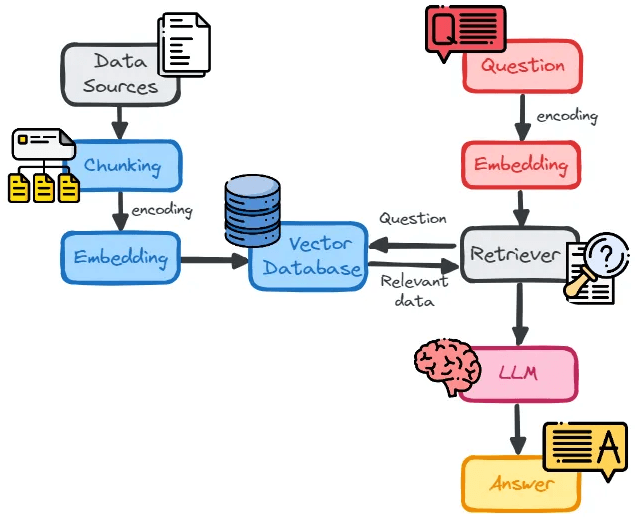
Un indice vettoriale è una struttura dati progettata per organizzare e cercare informazioni in uno spazio matematico, dove ogni elemento (ad esempio, una parola o un intero documento) è rappresentato come un vettore, cioè una serie di numeri che descrivono le sue caratteristiche.
Embedding
Questa rappresentazione numerica è il risultato di un processo chiamato embedding, che mappa le informazioni (testo, immagini, ecc.) in uno spazio vettoriale. In questo spazio, concetti semanticamente affini vengono collocati in posizioni vicine tra loro. Ogni contenuto diventa un punto in uno spazio ad alta dimensionalità (ad esempio, 768, 1536, 3072, 4096 dimensioni); la query dell’utente diventa un altro punto. Cercare significa trovare i vicini più prossimi nello spazio, cioè i contenuti semanticamente affini anche se le parole non combaciano.
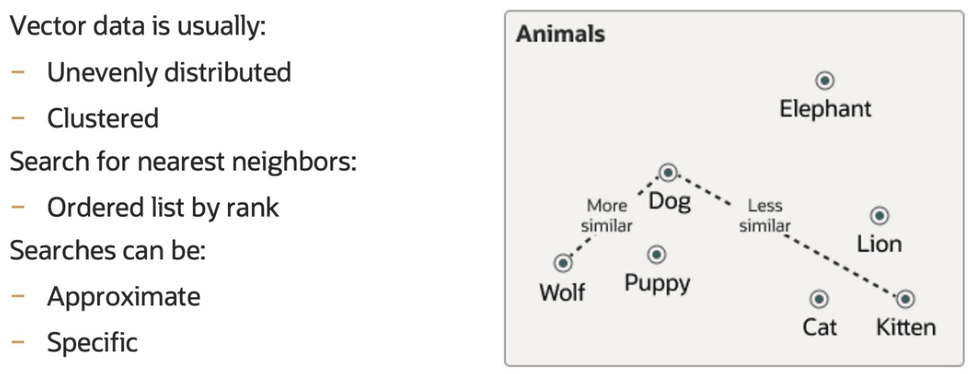
Ad esempio, se cerchi "gatto", un motore di ricerca basato su embedding potrebbe restituire risultati pertinenti anche per "felino" o "animale domestico", poiché ha compreso che questi concetti sono correlati.
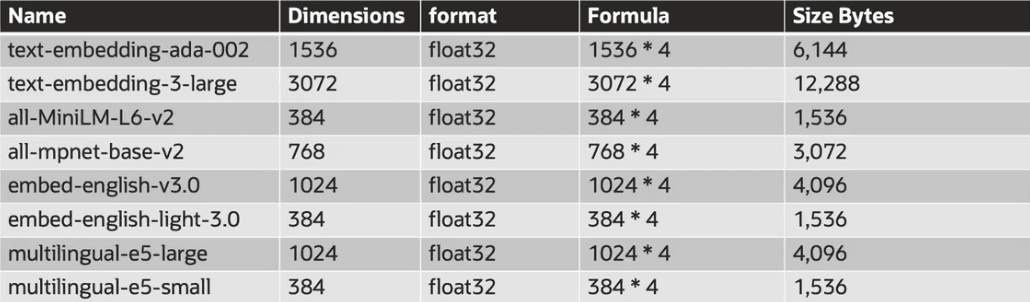
La dimensione del vettore definisce quanti numeri compongono il vettore:
- Precisione e capacità semantica: vettori di dimensione maggiore possono rappresentare meglio le sottigliezze e le relazioni tra concetti;
- Performance e costi: vettori più lunghi richiedono più spazio di archiviazione, più tempo di calcolo e più memoria per la ricerca.
Ogni dimensione è una variabile del vettore:
- 2D → coordinate (x, y)
- 3D → coordinate (x, y, z)
- 768D → coordinate (x₁, x₂, …, x₇₆₈)
È impossibile da visualizzare, ma matematicamente è lo stesso concetto: ogni oggetto (immagine, frase, utente, ecc.) è un punto in quello spazio, e la distanza tra due punti misura quanto sono simili.
Tokenizzazione
La tokenizzazione è un passo preliminare importante in questo processo. Consiste nel suddividere un testo in unità più piccole, chiamate "token", che possono essere parole, sottoparole o anche singoli caratteri. Una volta suddiviso il testo, i token vengono trasformati in vettori numerici tramite modelli di embedding.
I modelli di embedding, che si basano su reti neurali profonde, vengono addestrati su grandi quantità di dati per apprendere le relazioni semantiche tra le parole, consentendo loro di "capire" come i concetti sono collegati tra loro.
Come funziona la Ricerca
Le query di similarità, ovvero le richieste per trovare contenuti simili, si basano su metriche matematiche come la cosine similarity, la distanza euclidea, il dot product o la distanza L2. Queste metriche calcolano la vicinanza tra i vettori e determinano quanto siano semanticamente affini.
Hierarchical Navigable Small World
Per affrontare la sfida della ricerca veloce su grandi dataset, vengono utilizzati algoritmi di Nearest Neighbor Search (NNS), tra cui HNSW (Hierarchical Navigable Small World). Un grafo di prossimità, come quello utilizzato da HNSW, collega i vertici in base alla loro vicinanza reciproca, con i vertici più vicini che risultano collegati tra loro.
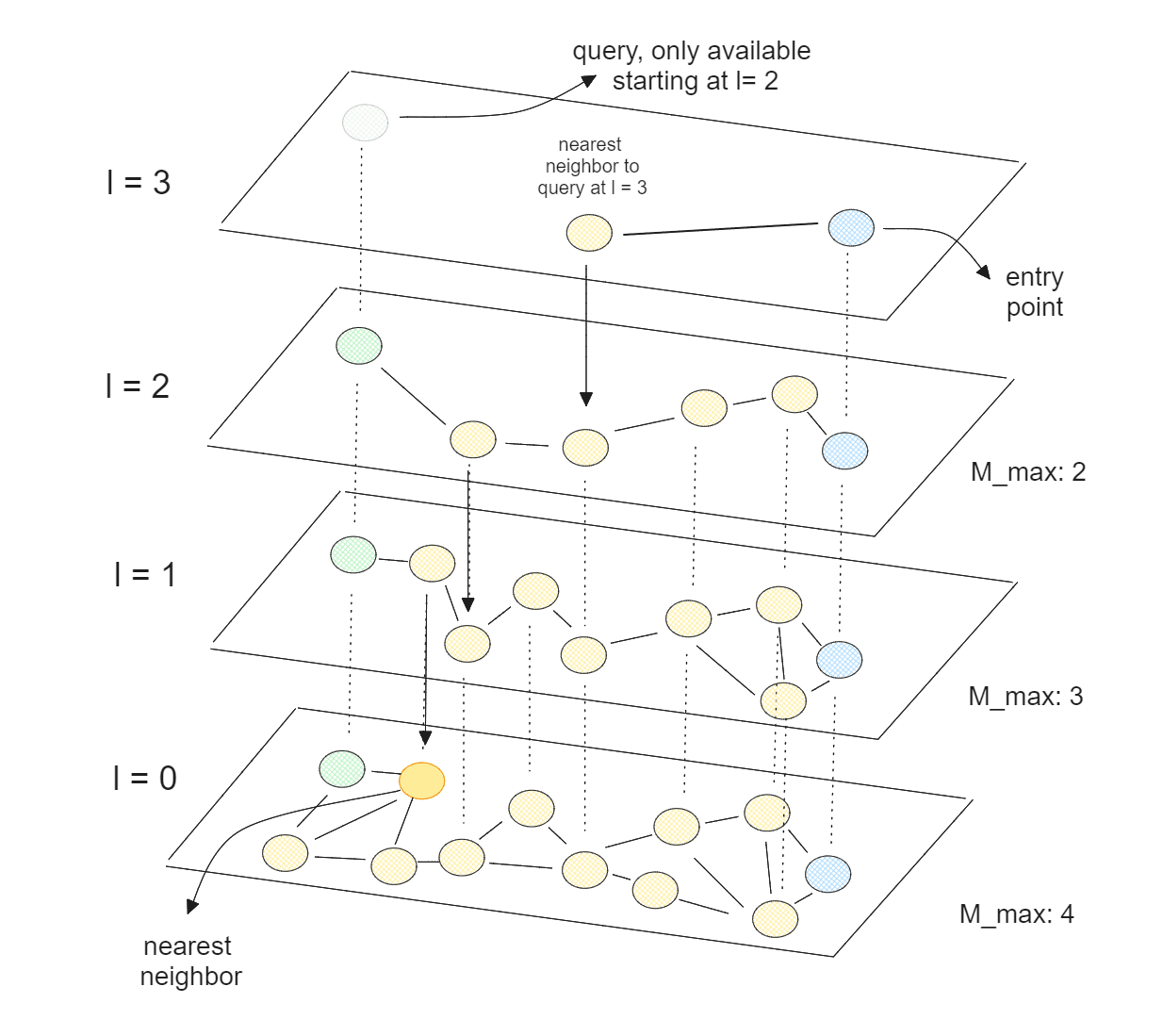
La struttura si basa su un concetto di grafi navigabili che si estende dal semplice grafo di prossimità a un grafo gerarchico. La gerarchia aggiunge un ulteriore livello di efficienza, riducendo il numero di confronti necessari per trovare i vicini più prossimi.
La ricerca in un grafo avviene in due fasi principali:
- Una fase iniziale di "zoom-out", dove si esplorano vertici con pochi collegamenti (basso grado);
- Una fase finale di "zoom-in", in cui si cercano i vertici con molti collegamenti (alto grado).
L'efficacia di HNSW è strettamente legata alla qualità del bilanciamento tra recall e velocità di ricerca. Se aumentiamo la media dei gradi dei vertici (cioè, il numero di collegamenti per vertice), la ricerca diventa più precisa, ma anche più lenta e complessa. Pertanto, bisogna trovare un giusto compromesso tra il grado dei vertici e la velocità della ricerca. Per migliorare le prestazioni, può essere utile iniziare la ricerca dai vertici con il grado più alto, concentrandosi prima sulle aree più dense del grafo, una tecnica particolarmente utile quando si lavora con dati a bassa dimensionalità.
La possibilità di costruire grafi che riducono il numero di confronti attraverso tecniche di clustering, partitioning e neighbor graphs rappresenta una delle ragioni principali per cui gli algoritmi come HNSW sono utilizzati in applicazioni pratiche.
Altri metodi
KNN (K-Nearest Neighbors) è un altro algoritmo di ricerca che può essere utilizzato in alternativa a HNSW, in particolare quando è richiesta ricerca esatta. KNN trova i vicini esatti più prossimi senza approssimazioni, garantendo maggiore precisione, ma è meno scalabile rispetto a HNSW, rendendolo più adatto per dataset di dimensioni contenute.
Un Neighbor Partition Vector Index è un altro metodo utilizzato per ottimizzare la ricerca in grandi dataset. L'idea alla base di questo indice è partizionare i vettori in gruppi basati sulla loro somiglianza semantica, interrogando solo le partizioni più rilevanti durante la ricerca.
Schema di un Indice
Un indice di ricerca organizza i dati in campi, ognuno dei quali rappresenta un tipo specifico di dato e determina come quel dato verrà trattato durante la ricerca.

Campi classici
- Edm.String: utilizzato per testi e stringhe (es. descrizioni, nomi, titoli).
- Numerici: per numeri interi o decimali (es. prezzi, quantità).
- Date: per valori temporali (es. date e orari).
Attributi
Ogni campo può avere uno o più attributi che definiscono il comportamento durante la ricerca:
Searchable: indica che il campo è indicizzato per la ricerca per parole chiave.
- Significa che il testo contenuto nel campo verrà analizzato e potrà essere utilizzato nelle query di ricerca, consentendo una ricerca basata su corrispondenza esatta o parziale.
Retrievable: campo che verrà restituito nei risultati di ricerca.
- Se un campo è marcato come retrievable, il suo contenuto verrà restituito nell'output della query.
Filterable: campo utilizzabile per applicare filtri.
- Se un campo è filterable, sarà possibile eseguire ricerche per estrarre solo i dati che soddisfano determinate condizioni, come "dove il valore di X è maggiore di Y".
Sortable: campo utilizzabile per ordinare i risultati.
- Se abbiamo un campo che rappresenta la data di inserimento (come un ID incrementale), puoi ordinare i risultati in base a questo campo, anche se non ti interessa visualizzarlo nell'output finale.
Facetable: campo utilizzabile per raggruppamenti.
- Questa funzionalità è molto utile per creare faccette di ricerca in applicazioni come i negozi online, dove gli utenti possono filtrare i risultati in base a categorie come brand, dimensione, colore, ecc.
Campi Vettoriali: per la ricerca semantica basata su similarità.
- Contengono vettori numerici e vengono utilizzati per eseguire ricerche semantiche.
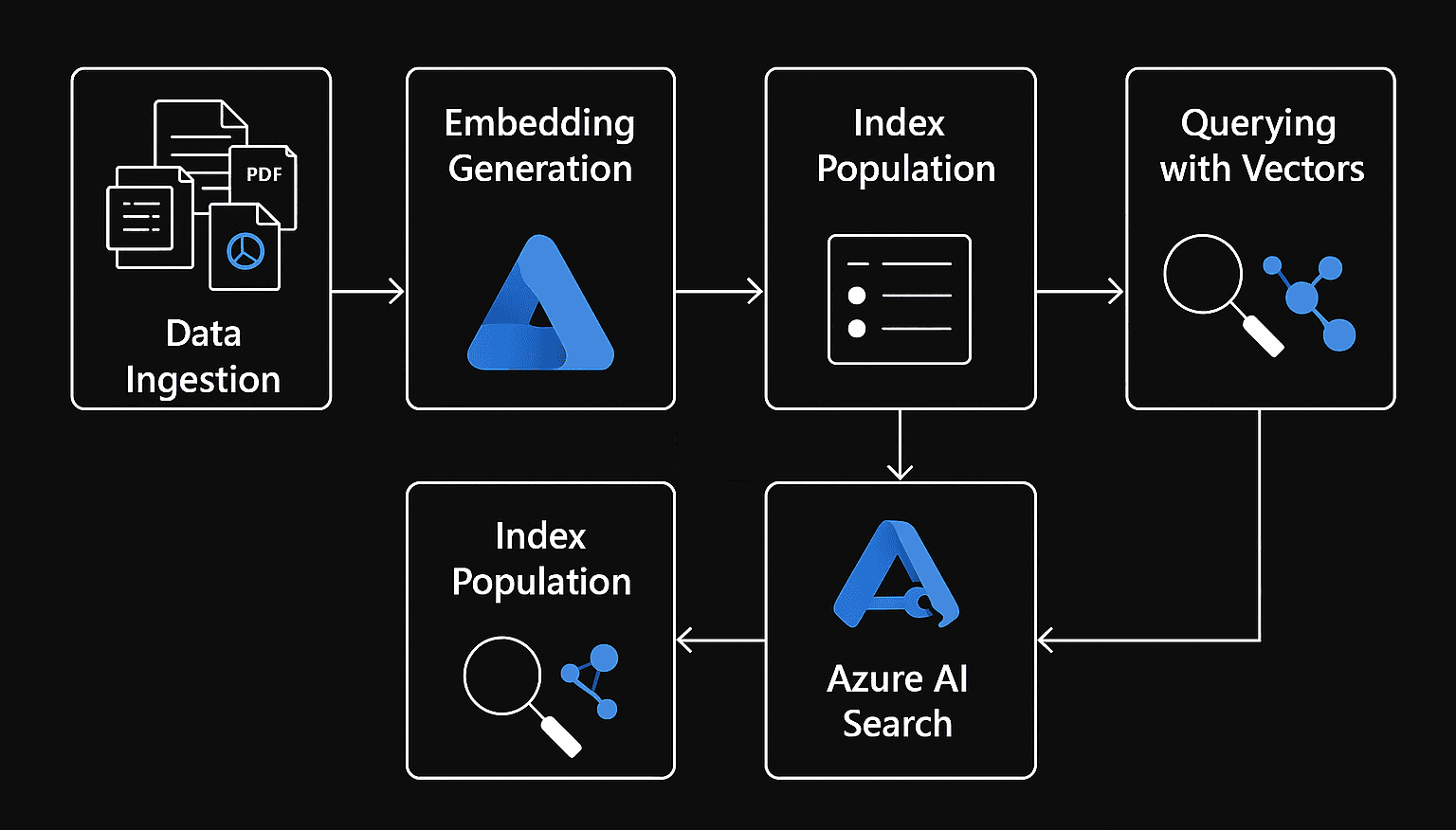
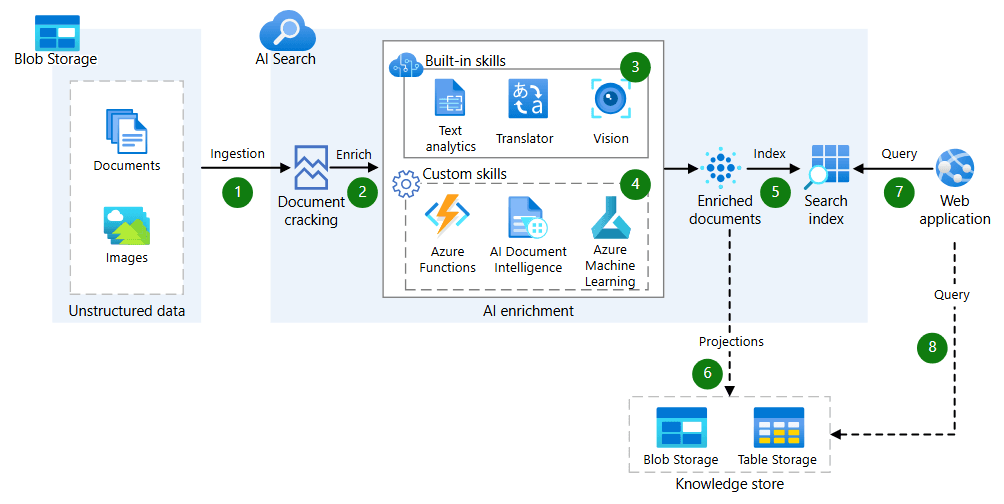
Azure AI Search
Azure AI Search è un servizio PaaS offerto da Microsoft Azure, progettato per aiutare le aziende a costruire e implementare soluzioni di ricerca avanzata su grandi volumi di dati.

Componenti
Il servizio si basa su un insieme di componenti che lavorano insieme per consentire l'indicizzazione, l'elaborazione e la ricerca dei dati in modo efficiente.
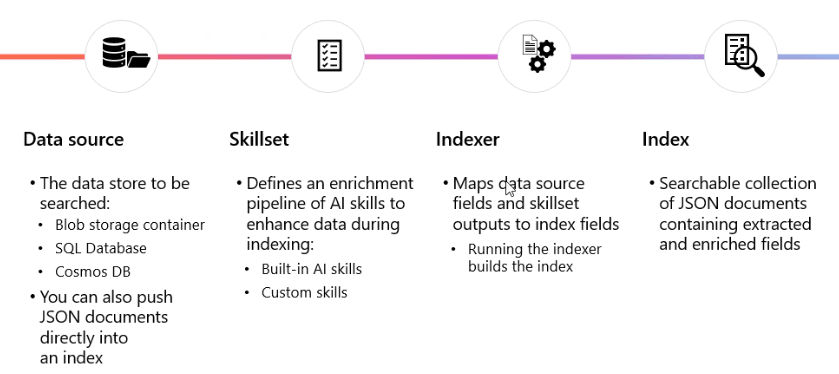
Data Source
E' la fonte primaria da cui l'indice viene popolato, il punto di partenza per qualsiasi operazione di ricerca.
Rappresenta il repository dei dati da indicizzare e può essere costituito da una varietà di origini, inclusi database SQL, file system, blob storage, data lake, o documenti JSON.
La connessione tra la sorgente dati e il processo di indicizzazione è automatica, il che significa che qualsiasi modifica, come l'aggiunta o la rimozione di documenti, viene automaticamente sincronizzata.
Skillset
E' una raccolta di operazioni che possono essere applicate ai dati prima che vengano indicizzati. Queste operazioni consentono di arricchire i dati o di estrarre informazioni utili per migliorare la qualità della ricerca.
Ad esempio, uno Skillset può includere:
- Analisi del testo: per estrarre informazioni da documenti di testo, come frasi chiave o entità.
- Estrazione di entità: per identificare e classificare entità specifiche come nomi di persone, luoghi, organizzazioni, ecc.
- Traduzione automatica: per tradurre testi da una lingua all’altra.
- Riconoscimento delle immagini: per estrarre informazioni da immagini, come il riconoscimento facciale o la lettura di testo contenuto in un'immagine tramite OCR (Riconoscimento Ottico dei Caratteri).
Le skill possono anche essere personalizzate per soddisfare esigenze particolari, come applicare modelli di machine learning per l'analisi avanzata o l'elaborazione dei dati.
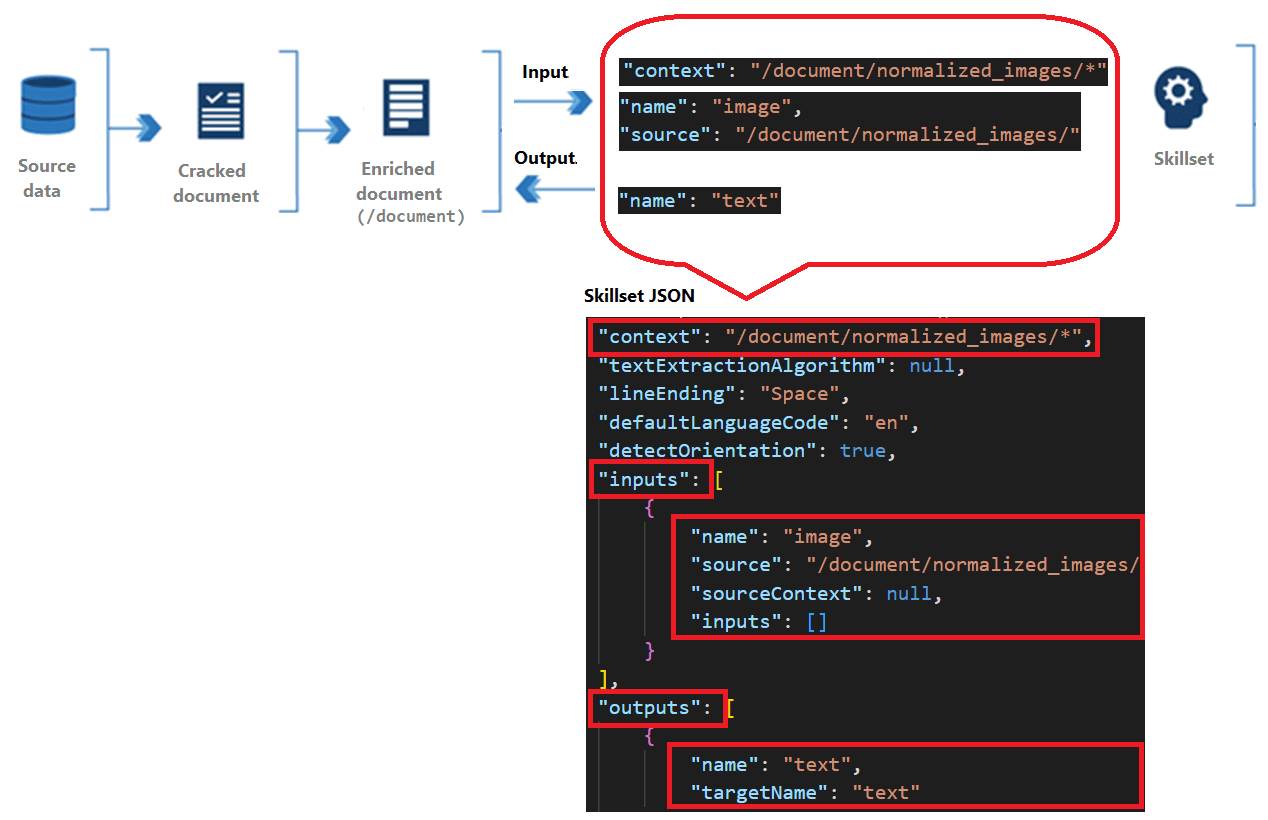
Grazie alla skill Text Split è possibile implementare il chunking:
- textSplitMode: definisce l'unità di suddivisione, ad esempio "pages" (pagine) o "sentences" (frasi).
- maximumPageLength: determina la lunghezza massima di ogni chunk in caratteri.
- pageOverlapLength: specifica la lunghezza dell'overlap tra i chunk consecutivi, utile per mantenere la coerenza semantica tra i segmenti.
Il chunking consiste nel suddividere un documento di grandi dimensioni in parti più piccole, chiamate "chunk", per facilitare l'elaborazione e la ricerca. Questo è particolarmente utile quando si utilizzano modelli di embedding, che hanno limiti sul numero di token (parole o frammenti di parole) che possono elaborare contemporaneamente. Suddividendo i documenti in chunk, si garantisce che ogni parte rientri nei limiti del modello, migliorando l'efficacia della ricerca semantica.
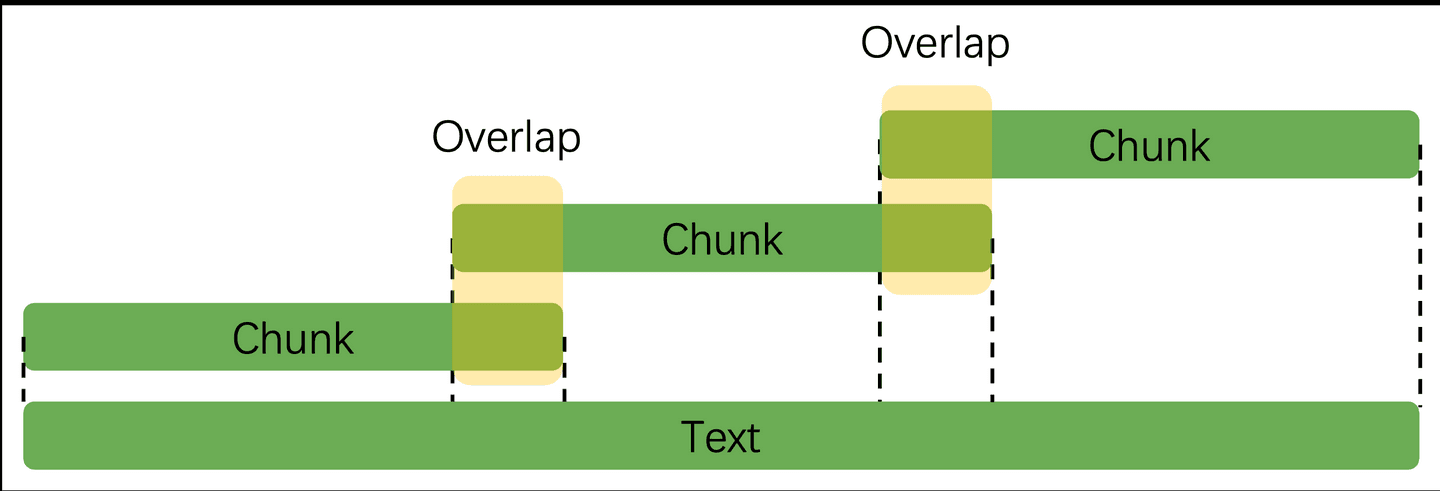
E' previsto un overlap tra i chunk per garantire che il contesto semantico non venga perso durante la suddivisione del documento in segmenti più piccoli.
- Preservazione del contesto: L'overlap permette di mantenere un collegamento semantico tra i chunk, assicurando che concetti, idee o entità trattati in un chunk possano essere compresi anche nel chunk successivo.
- Migliore qualità della ricerca: Quando si eseguono ricerche semantiche, l'overlap aiuta a evitare che il significato venga "tagliato" tra i chunk, migliorando la pertinenza dei risultati.
Indexer
E' la componente che si occupa di leggere i dati, applicare le skill definite, e infine popolare l'indice con i dati trasformati. In altre parole, è il "processo" che prende i dati grezzi e li trasforma in una struttura indicizzata, pronta per essere interrogata durante le ricerche.
Normalmente operano su base automatica e possono essere configurati per eseguire operazioni schedulate.
Index
E' la struttura finale in cui i dati vengono memorizzati dopo essere stati trasformati e arricchiti. In sostanza, è dove vengono conservati i dati indicizzati e pronti per essere interrogati tramite query di ricerca.
Un buon design è fondamentale per ottenere prestazioni elevate in ambienti con grandi volumi di dati.
Tipo di ricerca supportata
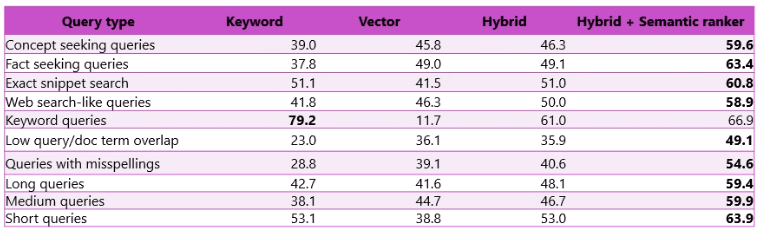
Ecco una sintesi dei principali tipi di retrieval supportati:
| Tipo | Possibilità | Caratteristiche |
|---|---|---|
| Full-text search | Ricerca su testo esatto/indicizzato | Veloce, keyword, text only |
| Vector search | Ricerca semantica su vettori generati da AI | Embedding LLM, similitudine semantica, supporto immagini |
| Hybrid search | Combinazione di keyword + similarity (vector) | Unisce vantaggi di full-text e vector, boost dei migliori |
| RAG | Recupero documenti + generazione risposta | Il modello LLM consulta risultati search e “elabora” la risposta |
| Agentic search | Agente (Copilot) che orchestra task o ricerche | Può combinare i metodi sopra in modo autonomo |
Processo di indicizzazione
Include una serie di fasi in cui i dati vengono estratti, eventualmente arricchiti, mappati e infine indicizzati, per essere pronti a rispondere alle query degli utenti.
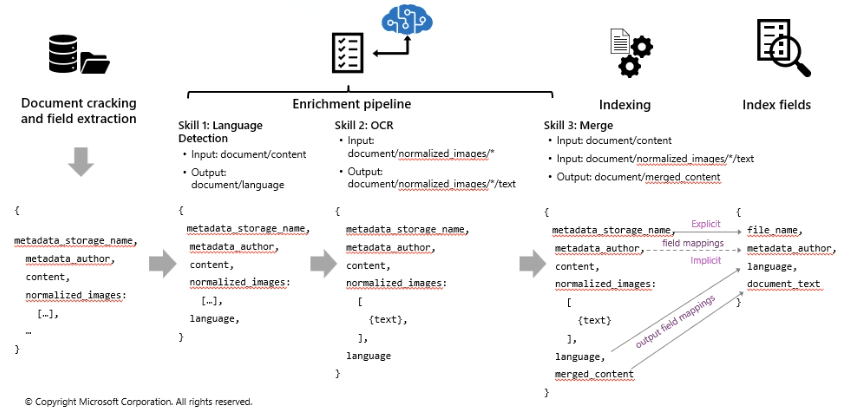
1 Field Mappings (espliciti e impliciti)
Stabiliscono come i dati provenienti dalla fonte debbano essere trattati nell'indice, determinando quali campi debbano essere searchable, retrievable, sortable, e così via.
Field Mappings Espliciti: Sono definiti manualmente per ogni campo;
Field Mappings Impliciti: Vengono assegnati automaticamente in base al tipo di dato.
- Ad esempio, i campi numerici vengono generalmente mappati come sortable o filterable, e i campi contenenti testo vengono mappati come searchable. Possono essere modificati se necessario.

Output Field
Gli output field mappings sono specifici per i dati arricchiti da skillset, e definiscono come le informazioni trasformate (ad esempio, tramite OCR o analisi semantica) devono essere memorizzate nell'indice di ricerca.
2 Enrichment Pipeline
Una volta che i dati sono stati estratti, si possono arricchire tramite una pipeline. Questa fase consiste nell'applicare Skillset.
Ecco alcuni esempi di skill comunemente utilizzate:
- Skill 1: Language Detection
L'operazione di language detection identifica la lingua di un documento e la aggiunge ai metadati. L'input di questa skill è il documento o il contenuto, e l'output è il documento arricchito con la lingua rilevata. - Skill 2: OCR (Optical Character Recognition)
Se i documenti contengono immagini con testo, l'OCR è utilizzato per estrarre il testo da queste immagini. L'input di questa skill sono le immagini normalizzate contenute nel documento, e l'output è il testo estratto da queste immagini, che verrà poi incluso nel documento finale. - Skill 3: Merge
Una volta che i dati sono stati arricchiti, il merge combina i vari contenuti (ad esempio, testo, metadati e testo estratto dalle immagini) in un unico documento. L'input è il contenuto originale del documento e l'output è il documento con il contenuto fuso e arricchito, pronto per l'indicizzazione.
3 Indexing
Il processo di indexing è il momento in cui i dati vengono trasformati in una struttura che può essere facilmente interrogata. L'Indexer si occupa di leggere i dati dalla sorgente, applicare le skill definite e infine popolare l'indice con i dati pronti per la ricerca.
Limiti e Implicazioni Etiche
Se da un lato la ricerca semantica apre scenari di business straordinari, è fondamentale riconoscerne i limiti operativi, i costi nascosti e le sfide etiche, per garantire un'implementazione responsabile e sostenibile.
Il successo di un sistema di ricerca vettoriale dipende criticamente dalla Qualità del Dato Sorgente. Se i dati di partenza sono scadenti o il chunking frammenta eccessivamente il contesto, anche l'indice vettoriale più avanzato produrrà risultati mediocri.
L'integrazione con i modelli LLM introduce rischi che devono essere gestiti attivamente:
- Ereditarietà del Bias: I modelli di embedding, sono addestrati su dati storici che riflettono inevitabilmente bias sociali, culturali o linguistici. Questo può portare a risultati di ricerca o risposte generate che discriminano involontariamente o rafforzano stereotipi.
L'uso di AI per l'analisi e la sintesi dei dati richiede una rigorosa governance:
- Trasparenza e Spiegabilità (XAI): Quando un sistema prende una decisione o genera una risposta è fondamentale sapere perché quel risultato è stato selezionato. I sistemi devono garantire la trasparenza sulle fonti utilizzate e sulle ragioni del ranking.
- Privacy dei Dati: L'analisi e l'indicizzazione di dati non strutturati (come email interne o documenti legali) devono essere condotte nel pieno rispetto delle normative sulla privacy, garantendo che i dati sensibili non vengano esposti in modo inappropriato, anche all'interno degli indici vettoriali stessi.
Conclusioni
Questi concetti non sono solo teorie astratte, ma sono il cuore pulsante delle soluzioni di IA integrata.
Capire come funziona la ricerca vettoriale, l'analisi del linguaggio naturale e la generazione di risposte basate su modelli RAG è essenziale per sfruttare appieno il potenziale dell'intelligenza artificiale.
Implementando la ricerca semantica avanzata basata su indici vettoriali, le aziende non si limitano a migliorare la tecnologia, ma ottengono un significativo Ritorno sull'Investimento (ROI) tangibile in tre aree chiave:
Miglioramento della Customer Experience (CX)
- Risposte Più Veloci e Accurate: I sistemi basati possono analizzare il contesto, recuperare i documenti e generare una risposta concisa e personalizzata. Questo riduce i tempi di attesa e aumenta la fiducia nel marchio.
- Riduzione del Tasso di Abbandono: Sia nell'e-commerce che nel supporto clienti, l'utente che trova subito ciò che cerca è un utente soddisfatto. I risultati altamente pertinenti aumentano la conversione.
- Supporto 24/7: Chatbot e assistenti virtuali potenziati offrono un supporto di livello quasi umano, disponibile continuamente.
Efficienza Operativa e Riduzione dei Costi
- Ricerca Aziendale Potenziata: I dipendenti possono trovare istantaneamente informazioni (policy, manuali tecnici, contratti legali) tra migliaia di documenti usando query in linguaggio naturale. Questo accelera i processi decisionali e riduce il tempo sprecato.
- Ottimizzazione della Logistica e della Catena di Fornitura: Analizzando i dati è possibile prevedere ritardi o ottimizzare percorsi, portando a risparmi sui costi operativi.
Insight Strategici e Vantaggio Competitivo
- Analisi Approfondita del Feedback: Trasformando recensioni, trascrizioni di chiamate e commenti sui social in vettori, l'IA può identificare i sentimenti e le correlazioni tra i problemi, andando oltre la semplice frequenza delle parole chiave. L'azienda ottiene una comprensione profonda di ciò che i clienti pensano e vogliono.
- Identificazione di Tendenze Emergenti: L'analisi semantica su articoli di settore, documenti di ricerca e brevetti consente di intercettare opportunità di mercato e rischi competitivi molto prima che diventino mainstream.
- Sviluppo Prodotto Mirato: Utilizzando gli embedding per mappare le caratteristiche dei prodotti esistenti rispetto alle lacune di mercato o alle richieste specifiche dei clienti, l'azienda può indirizzare lo sviluppo di nuovi prodotti con maggiore precisione, garantendosi un vantaggio competitivo sostenibile.
In un futuro in cui l'intelligenza artificiale diventa sempre più pervasiva, le tecnologie di ricerca semantica non sono solo un plus, ma una necessità per chi vuole rimanere al passo con l'evoluzione del mondo digitale e costruire soluzioni in grado di rispondere alle sfide moderne con maggiore velocità e precisione.
Riferimenti
- https://learn.microsoft.com/en-us/azure/search/search-what-is-azure-search
- https://docs.azure.cn/en-us/search/cognitive-search-concept-intro
- https://docs.azure.cn/en-us/search/vector-search-how-to-generate-embeddings
- https://docs.azure.cn/en-us/search/retrieval-augmented-generation-overview
- https://en.wikipedia.org/wiki/Hierarchical_navigable_small_world