Chunking - Il cuore invisibile dell'IA
-
Denis Dal Molin
- 08 Nov, 2025
- 05 Mins read

Negli ultimi mesi, l’adozione dell’Intelligenza Artificiale Generativa (GenAI) in ambito enterprise è in forte espansione.
Sempre più aziende vogliono integrare la propria conoscenza interna nei modelli di AI, per creare assistenti digitali, motori di ricerca semantica o piattaforme di knowledge management intelligenti.
Per ottenere risultati realmente affidabili e pertinenti, non basta “collegare” un modello linguistico a un archivio documentale. Serve un livello intermedio: una strategia di gestione e rappresentazione del contenuto.
Il modo in cui suddividiamo e prepariamo le informazioni influenza direttamente la qualità delle risposte.
Ed è qui che entra in gioco il chunking.
Cosa è il chunking e perchè è importante
Il chunking è una tecnica che consente di suddividere testi o documenti in blocchi più piccoli e coerenti, chiamati chunk.
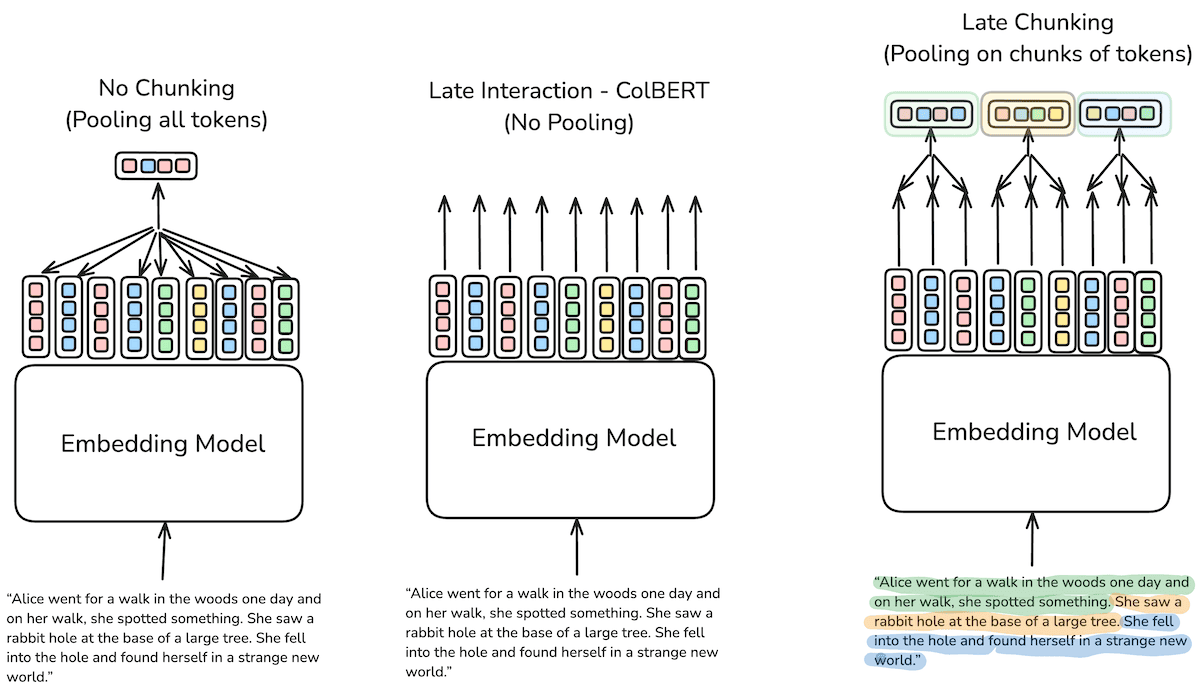
Questi frammenti vengono poi indicizzati e trasformati in vettori numerici (embedding), che permettono ai modelli linguistici di comprendere e confrontare il significato dei testi in modo semantico. In questo modo, ogni pezzo di testo diventa una rappresentazione comprensibile per i modelli linguistici, che possono calcolare la similarità semantica tra concetti e restituire risultati più precisi nelle fasi di retrieval e generazione.
Ad esempio:
- Un PDF di 10 pagine viene suddiviso in 30 blocchi di 300 caratteri ciascuno;
- Ogni blocco viene incorporato e memorizzato in un database per il recupero.
Il vincolo della Context Window e il ruolo della Tokenization
Il chunking lavora in sinergia con due altri concetti chiave:
- Tokenization: il processo con cui il testo viene “spezzato” in unità più piccole (token) che il modello può elaborare;
- Embedding: trasforma ciascun chunk in una rappresentazione numerica (un vettore) che ne cattura il significato semantico.
Ogni modello linguistico ha un limite massimo di context window, cioè il numero di token che può considerare contemporaneamente.
Per esempio, un modello con finestra da 16.000 token non può analizzare un documento intero da 100 pagine in un solo passaggio. Da qui nasce la necessità di spezzarlo in chunk più piccoli, garantendo che ciascuno rientri nel limite del modello e mantenga coerenza semantica.
La tokenization è il primo passo di questa ottimizzazione: trasforma le parole in unità numeriche (token) che il modello può elaborare.

Ottimizzare la tokenizzazione non è solo una questione di efficienza computazionale, influisce direttamente sulla precisione semantica e sul costo del sistema, poiché i modelli di AI vengono fatturati per token elaborato.
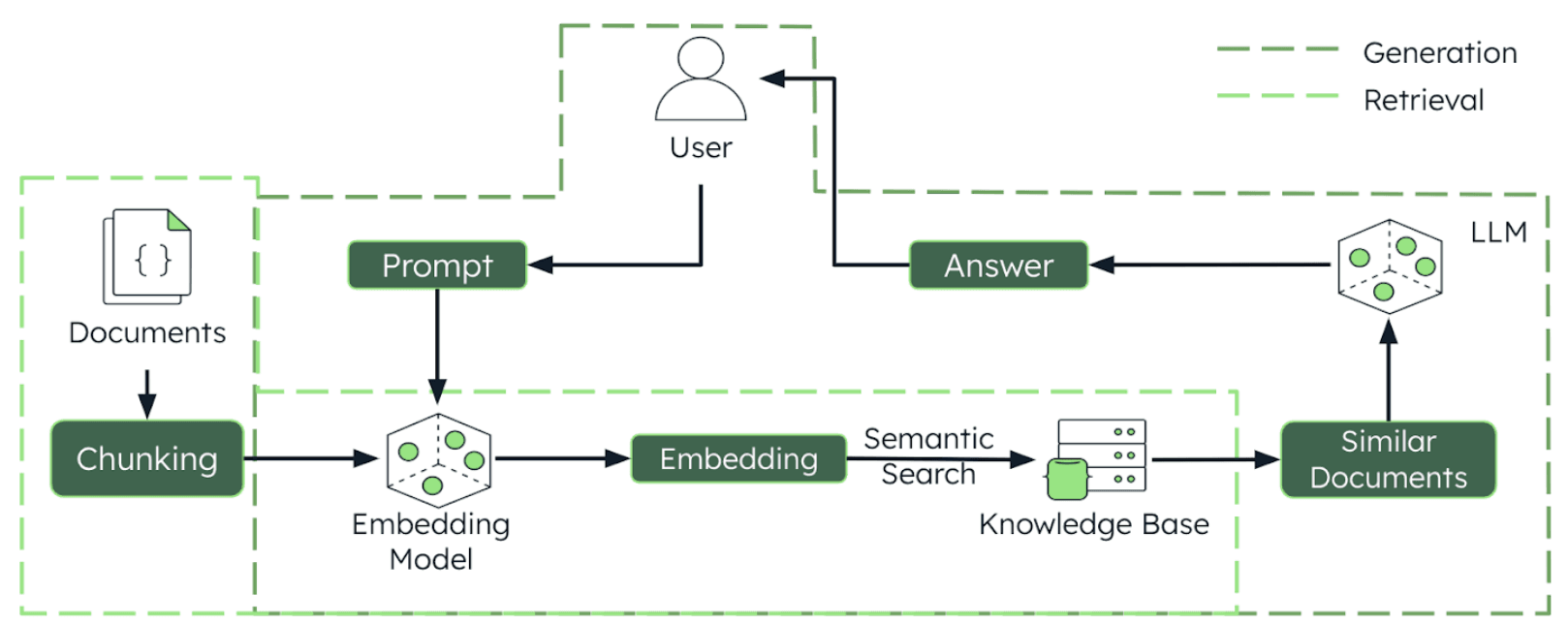
In pratica, il flusso tipico è questo:
- Un documento (es. PDF o Word) viene diviso in chunk coerenti;
- Ogni chunk viene tokenizzato e convertito in embedding;
- Gli embedding sono salvati in un vector database, pronti per essere interrogati da un motore di ricerca semantico;
- Quando l’utente pone una domanda, il sistema confronta la query con i vettori e recupera i chunk più rilevanti, che vengono poi forniti al modello per generare la risposta.
Chunk size e Overlap: precisione Vs contesto
La dimensione dei chunk è uno dei parametri più delicati da calibrare. Non esiste un’unica regola valida per tutti.
Chunk troppo grandi possono contenere molteplici argomenti, diluendo la pertinenza della ricerca semantica; chunk troppo piccoli rischiano di perdere il contesto e compromettere la coerenza della risposta.
La chiave sta nel bilanciare dimensione e coerenza semantica:
- Per applicazioni di ricerca e Q&A, chunk di 200–500 token sono spesso ideali.
- Per la sintesi di testi lunghi, si preferiscono chunk più ampi, fino a 2.000 token, per catturare una visione d’insieme.
- Nei contesti di analisi linguistica o sentiment analysis, chunk più piccoli (100–300 token) garantiscono maggiore precisione.
Per mitigare questo problema si usa l’overlap, ovvero una sovrapposizione parziale tra i chunk (in genere tra il 10% e il 20% del contenuto). L’overlapping permette di preservare il contesto tra le sezioni e garantire che informazioni cruciali ai bordi dei chunk non vadano perse.
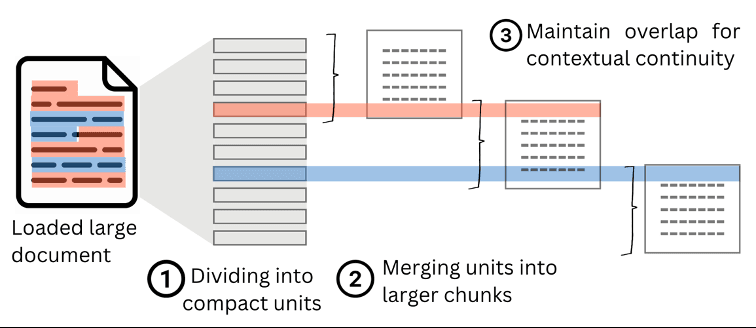
Un buon bilanciamento tra chunk size e overlap si traduce in risposte più precise e coerenti, e in una riduzione significativa delle allucinazioni.
Esistono diverse modalità per implementare questa sovrapposizione:
- Fixed-size Overlapping Chunks: È l'approccio più semplice, ogni chunk ha una dimensione fissa e una quantità definita di parole o frasi si sovrappone tra i chunk adiacenti;
- Variable-size Overlapping Chunks: I chunk variano in dimensione in base a segnali semantici o sintattici (ad esempio, terminano sempre alla fine di un paragrafo), ma mantengono comunque una sovrapposizione per preservare il contesto;
- Sliding Window Overlapping: Un approccio a "finestra scorrevole" che crea chunk sovrapposti muovendosi in avanti di un piccolo numero di token, parole o frasi ad ogni passaggio.
Il Valore Aggiunto dei Metadati
I metadati sono l'informazione aggiuntiva, possiamo immaginarli come delle etichette che aiutano a capire l'origine e la natura del contenuto.
Campi metadati comuni
- Nome Documento/ID: Per risalire immediatamente al file sorgente originale;
- Data, Fonte, Autore: Contesti extra come la data di pubblicazione o l'autore del contenuto.
I metadati sono un potente strumento per affinare la ricerca e la generazione di risposte:
- Filtro di Ricerca: Permettono di filtrare la ricerca prima del confronto vettoriale. Ad esempio, si possono recuperare solo chunk provenienti da tabelle o scritti da un autore specifico;
- Tracciabilità (Source Tracing): Quando un chunk viene recuperato, i metadati mostrano esattamente da dove proviene nel documento originale, un elemento chiave per la trasparenza e la verifica delle risposte fornite;
- Aumento di Rilevanza (Boosting): Possono migliorare il posizionamento dei risultati di ricerca. Se l'utente chiede dati recenti, i chunk con un metadato di data più recente possono essere automaticamente classificati più in alto, aumentando la freschezza e la pertinenza delle risposte.
Strategie di Chunking: non tutti i documenti sono uguali
In base al contenuto e all’obiettivo, esistono diverse tecniche di chunking, ognuna con vantaggi e compromessi.
Tra le principali:
- Fixed-size chunking: divide il testo in blocchi di lunghezza costante (caratteri, parole o token). È semplice e veloce, ma può interrompere frasi o concetti.
- Sentence-based o paragraph-based: sfrutta la struttura grammaticale del linguaggio per mantenere coerenza logica.
- Semantic chunking: utilizza embeddings o modelli NLP per individuare confini “naturali” tra concetti, garantendo che ogni chunk mantenga un significato completo.
- Recursive chunking: parte da sezioni ampie (es. paragrafi o capitoli) e le suddivide progressivamente finché ciascun chunk rientra nei limiti di token previsti.
- Hierarchical e metadata-aware chunking: conserva la struttura del documento (es. titoli, sezioni, fonti) per facilitare la tracciabilità e migliorare la pertinenza delle risposte.
- AI-driven o agentic chunking: sfrutta un modello LLM per decidere dinamicamente dove effettuare le divisioni, adattandosi al contenuto e all’intento utente.
| Method | Basis | Preserves Meaning | Complexity |
|---|---|---|---|
| Fixed-Size | Length-based | ❌ | Low |
| Sentence-Based | Natural language | ✅ | Low |
| Recursive | Structure | ✅✅ | Medium |
| Semantic | Meaning | ✅✅✅ | High |
| Hierarchical | Structure | ✅✅✅ | High |
| Modality-Specific | Content type | ✅✅ | Medium |
| AI-Driven Dynamic | Adaptive, LLM-based | ✅✅✅ | Very High |
| Agentic | Strategic, intent-aware | ✅✅✅ | Very High |
In ambito aziendale, la scelta dipende dal tipo di documentazione (manuali, report, email, presentazioni) e dal caso d’uso: ricerca semantica, chatbot interno, assistente tecnico, etc...
Valutare e ottimizzare la qualità del chunking
Come ogni componente architetturale che incide sulla qualità complessiva del sistema, anche il chunking va misurato.
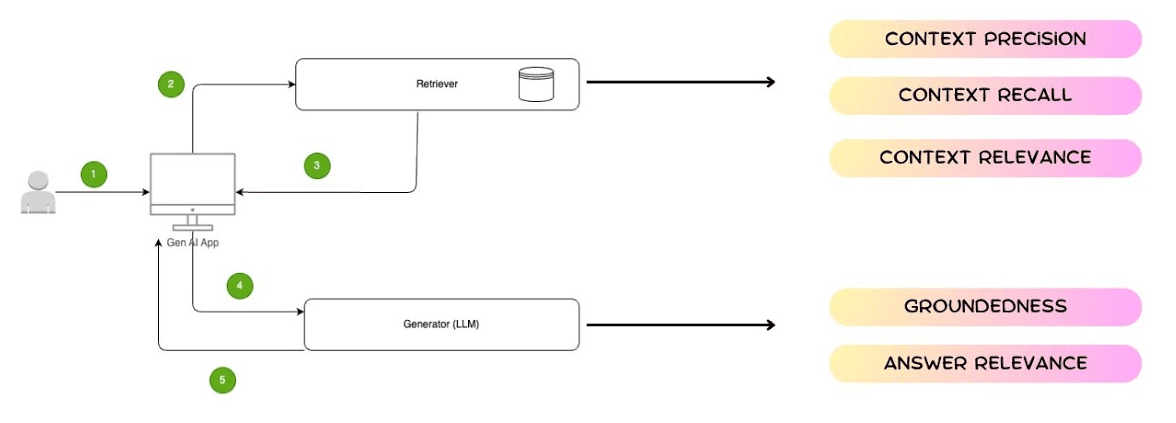
Alcune metriche utili per valutare l’efficacia del processo includono:
- Context precision: percentuale di chunk recuperati che risultano effettivamente rilevanti per la query;
- Context recall: misura quante delle informazioni pertinenti presenti nel database sono state effettivamente ritrovate;
- Context relevance: grado di allineamento semantico tra la query utente e i chunk restituiti;
- Chunk utilization: porzione di contenuto del chunk effettivamente usata dal modello per formulare la risposta (utile per identificare chunk troppo ampi o rumorosi);
- Chunk attribution: capacità del sistema di identificare in modo trasparente quali chunk hanno contribuito alla risposta finale.
Queste metriche aiutano a verificare che il chunking non sia solo efficiente dal punto di vista computazionale, ma anche semantico e informativo, permettendo di tarare dimensioni, overlap e strategie di retrieval nel tempo.
Integrazione nel mondo Azure
In Azure, questa integrazione si concretizza in un ecosistema di servizi che collaborano in modo sinergico.
Una tipica architettura RAG può includere:
- Azure OpenAI Service: per l’elaborazione e la generazione del linguaggio naturale;
- Azure Cognitive Search: come motore di indicizzazione e retrieval vettoriale (con supporto a embeddings e hybrid search);
- Azure AI Document Intelligence: per l’estrazione e la strutturazione dei contenuti dai documenti;
- Storage e Data Lake (es. OneLake o Blob Storage): come repository documentale primario.
In questo contesto, il chunking rappresenta la fase critica di pre-processing: il momento in cui i dati vengono trasformati da documenti testuali a conoscenza semantica strutturata, pronta per essere interrogata e compresa dall’AI.
Conclusione
Il chunking non è un semplice dettaglio tecnico: è la base architetturale su cui poggia la qualità dell’AI aziendale.
Un sistema di Intelligenza Artificiale Generativa è tanto efficace quanto la precisione con cui sa organizzare, indicizzare e contestualizzare le informazioni.
Progettare il chunking con metodo significa progettare la comprensione stessa del modello.