Ransomware? You want to battle, here's a war
-
Mattia Parise
- 10 Sep, 2021
- 05 Mins read

##Let's suppose you are an IT Manager: you have duties and responsibilities. Your latest project was very hard it's not finished yet. You and your team worked on it 100 days but due to some issues it's still not closed yet. ** That's a typical scenario in the IT world, let's be honest.**
Assuming you are a human, you also need some time to rest every often.
That being said, during Christmas holidays, you go on Holiday to show people how good you are snowboarding and to enjoy a bit your life. It's 1:30 PM, you are eating a big sandwich, waiting to get back on track, and you receive an alert from your monitoring system: your production Oracle server is down. You start wondering "how come? We fixed the last issue, it has been stable since 10 weeks!". After 20 seconds, second alert. Your Business Intelligence servers are not responding anymore. All of a sudden, your smartphone becomes crazy, a notification every millisecond: a big part of the infrastructure seems inactive, even the file server.
When you start realizing what's really happening, your phone starts ringing. Managers start calling you. First reaction: shock!
Last but not least, you get a Whatsapp message with this image attached saying
"We are seeing this on our PCs. What shall we do?"
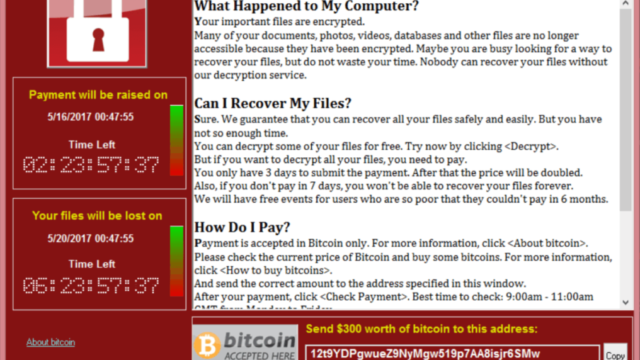
This is the right time where people start questioning theirselves: "Why me?" "Why did they try to attack people like me?" "My systems were not ready for production and all the other systems were certified with AV vendor"
There's a simple answer to all of these questions. And it's Kiwicon 2009 manifesto. Hackers simply...don't care (please don't start with the neverending war "hacker vs cracker").

So, what to do in this scenario? 3 steps usually are suggested
- isolate the infrastructure
- pay attention at infected servers
- when they are shutdown, it is possible they won't powerup
- better snapshot them before shutting them down
- isolate them
- don't panic, don't restore ANYTHING immediately
What's next? Next there's the real battle... Panic is everywhere, reliability becomes a question: nothing is certain anymore.
Backups are there? What can we do? I need someone who can help me in this nightmare!
When I think about battles, a song I love to listen is "You want a battle? Here's a war" from Bullet for my Valentine. (https://www.youtube.com/watch?v=Sno_2g8Y-jI)
THE Question
Do you have a disaster recovery playbook? No is not an accepted answer in this situations.
Reality is: NO. This is a common answer, so not having the playbook is a common scenario. This is the right time where having a recovery team helps a lot.
In order, the team must work with cohesity and attention for every step of the "imaginary" recovery playbook .
- Know where you have fallen You can't restore if you don't know where you have been infected. Never start a restore in a non-isolated scenario. Never start a restore of something you don't know if it's compromised or not.
- Recover the data protection infrastructure The recovery time for the backup infrastructure depends on the complexity of the environment. You need to know where the backups are stored, check if they are compromised and restore from them. Then you need to rebuild everything. Look for storage snapshots, offline backups, whatever you can rely on.
- Tiered level restore You need to know dependencies between applications. Otherwise, your recovery will fail, and you'll need more time to restore applications to a production state.
- Protect again your systems after recovery After recovery, remember to backup again the applications. No one wants a data loss in critical situations...
Challenges for the System Integrator
- You need to work as a team
- Divide the ownership for each activity but be synchronized
- Rotate people so you are forced to document everything
- On-site support
- Knowledge transfer after each activity / day
From the System Integrator perspective, it's not easy to stop everything and send all your people to the customer site. This action can be performed only if you are not loaded of work, which is barely impossible since COVID-19 started (at least for our team). The challenge here is to handle even this emergency as a project. In this scenario, a recent real world example became our template for the next steps. We created some roles to face the next emergencies. Let's share all of them
- Emergency Data Management Solution Architect The goal of the Emergency Data Management Solution Architect (EDMSA) is not to design a solution with "best practices". This is more complex than ever. The EDMSA needs to be able to * understand the attack surface and the current situation * plan a feasible and plausible recovery scenario * understand what the customer provides as a recovery environment * create an isolated recovery environment (IRE), with the help of the customer, in the shortest time possible * analyze the current bottlenecks and think about possible RTOs (restricted by first restore performance) with the current environment * recover the data protection infrastructure and make it running properly, ready-to-restore * support the customer in the most critical restore operations * document to the team the new temporary (or not) backup infrastructure * act as a focal point for the entire recovery process
- Emergency Senior Data Management Engineer The goal for the Emergency Senior Data Management Engineer (ESDME) is to help the customer with the most critical restores. Issues, especially without a Disaster Recovery playbook (and tested procedures) can and may happen. This is when a senior engineer is requested: experience is fundamental in this phase. It helps making the entire recovery process faster. For the critical applications, low RTO is necessary.
- Data Management Specialist When most critical apps are restored and the infrastructure is, even "ad temporum", in production state, the Data Management Specialist is ready to do most of the activities that still need to be done. This role acts as the principal owner for restores and recoverability, but that's not his only accountability. It also has the responsibility to make the backup infrastructure work as expected. When things go back to production, they NEED to be backed up again immediately: the risk for data loss is too high to leave the recovered applications without protection.
Our recent recovery required a lot of people to be involved. A lot of work has been done and I'm proud to say that we didn't lose any minute, giving the customer the experience of a "service" there for him, ready to recover everything from backups. There's one thing to say. Long story short, not every customer is so lucky: not every customer has the backups untouched and recoverable after a cyberattack. Most of the victims usually have the backup deleted or encrypted. There are a lot of measures to protect backups.
If you don't know what to do,
- start looking for "Backup immutability" and see what features you can leverage to achieve this goal.
- isolate your backup infrastructure from production network! Flat network is bad!
- watch the "Zen, Ransomware, and the Art of Data Protection Maintenance" from Download 2021 - sorry, it's in italian language (https://www.youtube.com/watch?v=ewWpHx_LICc) ;)