Azure Kubernetes Service - Apache Superset deployment
-
Denis Dal Molin
- 04 Apr, 2024
- 08 Mins read

Introduzione
Negli ambienti aziendali moderni, l'analisi dei dati è diventata un elemento cruciale per prendere decisioni strategiche e guidare il successo. In questo contesto, strumenti come Apache Superset giocano un ruolo fondamentale, offrendo potenti funzionalità di business intelligence.
Per sfruttare appieno le potenzialità del software e garantire un'esperienza ottimale agli utenti che usufruiranno del servizio, è essenziale fornire un ambiente infrastrutturale robusto e scalabile. Nel caso specifico, ci siamo trovati di fronte alla necessità di distribuire un servizio per la business intelligence aziendale. L'attuale ambiente, ospitato nel cloud Azure, consisteva in alcuni servizi PaaS come database e cache Redis e una macchina virtuale. Sebbene questo ambiente fosse stato fondamentale per lo sviluppo e i test iniziali, è emersa la necessità di una distribuzione più orientata alla produzione.
Adottando un approccio cloud-native basato su microservizi si è reso necessario svincolare alcuni concetti come l'utilizzo della macchina virtuale, che costituiva un elemento monolitico nell'infrastruttura.
Scelta architetturale
Un passo fondamentale è stato quello di definire l'architettura più adatta per ospitare Apache Superset. Basandoci sulle best practice consigliate dal vendor, inizialmente si sono considerate due opzioni:
- distribuzione su Kubernetes
- distribuzione con Docker Compose
Queste due possibilità differiscono nel modo in cui gestiscono la scalabilità, l'orchestrazione dei container e la gestione delle risorse. Sebbene Azure Container Instances offra un'opzione di deployment rapida e senza gestione per i container Docker, abbiamo constatato delle limitazioni nel suo utilizzo per lo use case specifico.
Dopo una valutazione attenta, abbiamo optato per Kubernetes come piattaforma di orchestrazione. La decisione è stata guidata non solo dalle raccomandazioni del vendor, ma anche dalla necessità di adottare un'architettura in grado di soddisfare al meglio le caratteristiche e le esigenze del progetto.
Apache Superset
Apache Superset è una piattaforma** open-source** per la visualizzazione dei dati e l'analisi di informazioni. Attraverso un'ampia gamma di grafici, dashboard interattive e strumenti di analisi, si è affermato come uno dei principali strumenti nel panorama della business intelligence.
La piattaforma viene fornita con una serie completa di API disponibili, queste API sono accessibili attraverso un client Swagger integrato che rende disponibile l'elenco insieme alla documentazione associata e ai test harness che gli sviluppatori si aspettano.
Architettura Apache Superset
Apache Superset è costruito interamente su Python e consiste in:
- Web server
- Metadata database
- Cache layer
- Message queue per le query asincrone
I principali elementi sono:
- Frontend
- React / Redux
- webpack / eslint / jest
- Suddiviso in tanti pacchetti @supserset-ui/
- nvd3, data-ui (VX), blocks, ...
- Backend Python
- Flask App Builder
- framework open-source per lo sviluppo di applicazioni costruito sulla base di Flask
- utilizza FAB per abilitare la sua architettura MVC e le sue funzionalità di sicurezza
- Profilo utente
- Viste per la reimpostazione della password
- Viste per la gestione degli utenti
- Viste di sicurezza
- Home page
- supporta diversi tipi di metodi di autenticazione popolari
- OAuth e Open ID
- LDAP
- Database
- SQLalchemy (ORM + SQL toolkit)
- è una libreria open-source scritta in Python che fornisce un'interfaccia di alto livello per lavorare con database relazionali
- Pandas
- Varie utils (sqlparse, dateutils, ....)
Superset è organizzato in due directory principali:
- superset (architettura MVC based costruito on top FAB)
- superset-frontend (componenti React, charts, fonts, CSS, image assets, etc..)
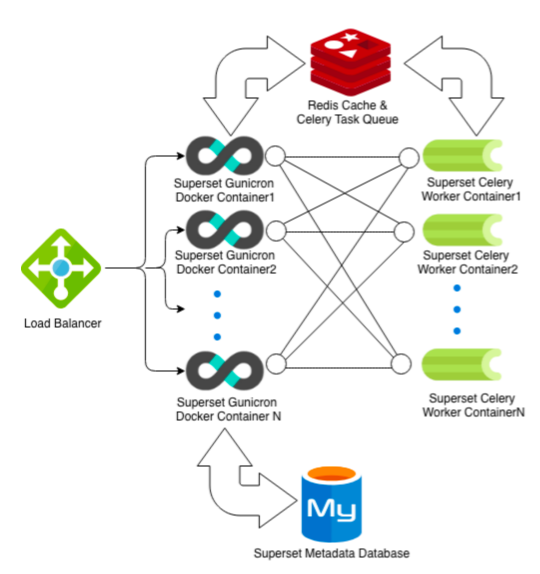
- load balancer per instradare le richieste dei client
- superset è il gruppo di server web gunicorn (per fornire la user interface)
- mysql è il gruppo metastore (db dei metadati di superset)
- redis è un gruppo di cache
- strato di cache e code di attività Celery per i worker (container per eseguire query in modalità asincrona)
Celery è un sistema distribuito per l'elaborazione di grandi quantità di messaggi, una coda di task si concentra sull'elaborazione in tempo reale, supporta anche la schedulazione programmata. Le code di task sono utilizzate come meccanismo per distribuire il lavoro tra thread o macchine.
Azure Kubernetes Service
Kubernetes è un sistema open-source per automatizzare la distribuzione, il ridimensionamento e la gestione di applicazioni containerizzate su più nodi offrendo un approccio dichiarativo, supportato da un robusto set di API per le operazioni di gestione.
Azure Kubernetes Service (AKS) è un servizio cloud, offerto da Microsoft Azure, che consente di eseguire cluster Kubernetes senza gestire l'infrastruttura sottostante.
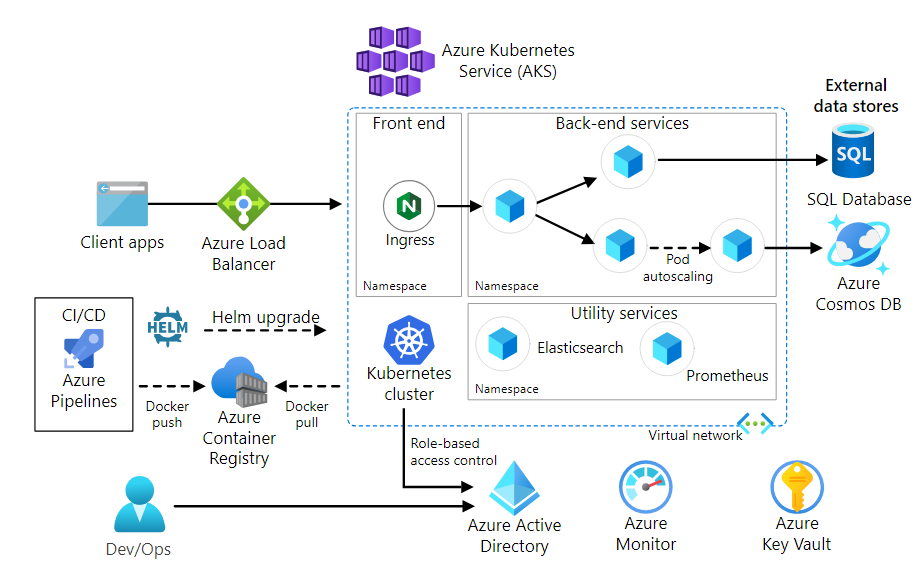
- Ingress (controller): fornisce un percorso HTTP/HTTPS per accedere ai servizi del cluster
- Dietro di esso, in genere si implementa un gateway API per gestire l'autenticazione e l'autorizzazione *Azure Load Balancer: utilizzato per instradare il traffico in entrata verso l'ingress
- Archiviazione esterna dei dati: i microservizi sono solitamente stateless e salvano i dati esternamente, come database relazionali o NoSQL
- Azure Container Registry (ACR): utilizzato per archiviare le immagini Docker dell'organizzazione e utilizzarle per distribuire i container nel cluster
- Azure Pipelines fa parte del servizio Azure DevOps e può aiutare nell'automatizzare alcuni cicli, in alternativa è possibile utilizzare una soluzione CI/CD di terze parti come Jenkins
I nodi AKS vengono eseguiti su macchine virtuali Azure (Scale Set).
Architettura cluster Kubernetes
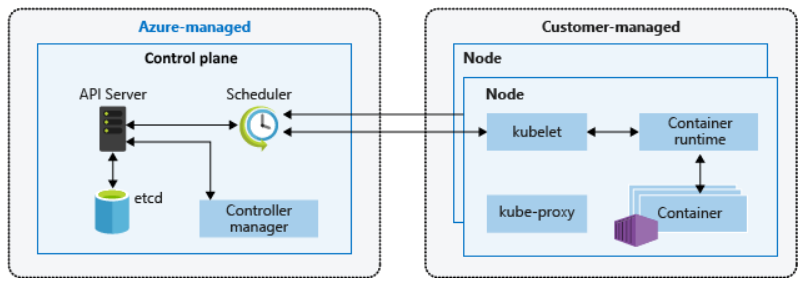
Un cluster Kubernetes è diviso in due componenti:
- Control plane: fornisce i servizi fondamentali di Kubernetes e l'orchestrazione dei carichi di lavoro delle applicazioni
- Nodi: eseguono i carichi di lavoro delle applicazioni
Kubernetes utilizza i pod per eseguire un'istanza dell'applicazione, in genere hanno una mappatura 1:1 con un container ma in scenari più avanzati un pod può contenere più container. Un pod è una risorsa logica, i carichi di lavoro delle applicazioni vengono eseguiti sui container.
In AKS, i nodi con la stessa configurazione sono raggruppati in pool di nodi (node pools). I node pool di sistema hanno lo scopo di ospitare pod di infrastruttura critici come CoreDNS e metrics-server, mentre i node pool utente hanno come scopo principale ospitare i pod delle applicazioni.
Il deployment è un oggetto che definisce lo stato desiderato di un'applicazione all'interno di un cluster, controlla rollout e gestione delle istanze delle applicazioni.
L'interazione con il control plane avviene attraverso le API di Kubernetes, tramite comand line kubectl o la dashboard. Tra le componenti del control plane ci sono:
- kube-apiserver: server che espone le API fornendo interazione con gli strumenti di gestione come la dashboard o kubectl
- etcd: è un archivio chiave-valore necessario per mantenere lo stato del cluster e della configurazione
- kube-scheduler: determina quali nodi possono eseguire il carico di lavoro e li avvia
- kube-controller-manager: supervisiona una serie di controller più piccoli che eseguono azioni come la replica dei pod e la gestione delle operazioni sui nodi
I nodi contengono invece:
- kubelet: agente che elabora le richieste di orchestrazione dal control plane e pianifica ed esegue i container
- kube-proxy: gestisce la rete virtuale instradando il traffico e gestendo l'indirizzamento IP per servizi e pod
- container runtime: in AKS viene usato containerd, nelle versioni precedenti veniva usato docker
In questo articolo, eviteremo di approfondire ulteriormente altri concetti di Kubernetes, concentrandoci principalmente sui fondamenti senza entrare nei dettagli più complessi legati alla gestione della rete (come kubenet, CNI, CNI overlay, Calico) e ai servizi.
Con Chocolatey è possibile installare la kubectl in Windows con il comando choco install kubernetes-cli
Helm
Helm è un packet manager open-source per Kubernetes progettato per semplificare il processo di deployment, aggiornamento e rollback delle applicazioni su un cluster Kubernetes. Helm introduce il concetto di "chart", che rappresenta una collezione di file YAML che definiscono un'applicazione Kubernetes pre-configurata e pronta per il deployment.
Un file chart solitamente include:
- file chart.yaml: contiene metadati sul chart, come il nome, la versione, la descrizione e l'autore
- cartella "templates": contiene i manifest Kubernetes scritti in YAML che definiscono i vari oggetti necessari per l'applicazione come pod, deployment, service, ingress e così via
- file **values.yaml **(o altri file di valori): contengono i valori predefiniti o personalizzati che possono essere utilizzati per configurare l'installazione del chart, gli utenti possono sovrascrivere questi valori di default durante l'installazione del chart per adattarlo alle loro esigenze
- file chart.lock: registra le versioni esatte delle dipendenze del chart, garantendo la riproducibilità delle installazioni
- cartella "charts" (opzionale): contiene eventuali dipendenze del chart, cioè altri chart utilizzati dall'applicazione
Helm, una volta installato, fornisce una serie di comandi da utilizzare dalla riga di comando per gestire chart e release
- helm install: per installare un chart
- helm upgrade: per aggiornare una release esistente con una nuova versione
- helm uninstall: rimuove completamente il deployment specificato, inclusi tutti i manifest di oggetti associati ad esso (come pod, servizi, segreti, ConfigMaps, etc..)
- helm list: mostra un elenco delle release installate
- helm repo add: aggiunge un repository di chart
- helm search: cerca chart disponibili nei repository configurati
- helm version: controlla la versione installata
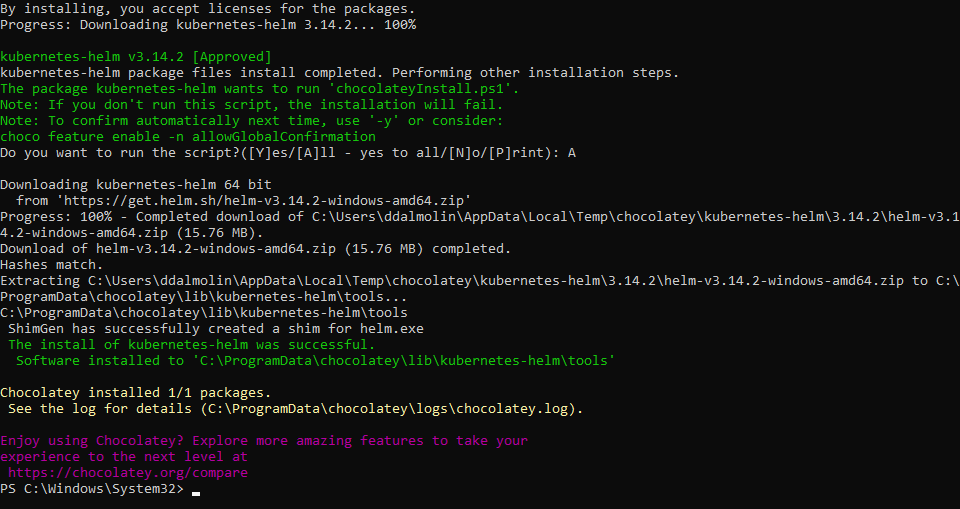
Sempre grazie a Choco, in Windows, si può installare velocemente usando il comando choco install kubernetes helm
YAML
In YAML, i dati sono rappresentati tramite una combinazione di elenchi, mappe e valori scalari, utilizzando una sintassi di indentazione per definire la struttura gerarchica dei dati. Una delle caratteristiche distintive è la sua natura umanamente leggibile, la sintassi minimale e l'assenza di caratteri speciali lo rendono facilmente interpretabile anche da chi non è esperto in programmazione.
Ad esempio, in un contesto Kubernetes, i file di configurazione YAML vengono utilizzati per definire le risorse dell'applicazione, come deployment, service e ingress, specificando i dettagli di configurazione necessari per il corretto funzionamento dell'applicazione all'interno del cluster Kubernetes.
Soluzione implementata
Step-by-step
Per implementare la soluzione, abbiamo seguito un approccio metodico e pianificato, come ben noto a coloro che già ci seguono sul blog.
Per garantire una corretta configurazione del cluster Kubernetes su Azure utilizzando il modello bring your own VNet con Azure CNI anziché Kubenet, è stato necessario predisporre una Virtual Network (VNet) con subnetting appropriato per ospitare i vari servizi che sarebbero stati integrati. Si è fatta particolare attenzione al piano di indirizzamento IP tenendo conto delle attività di manutenzione e aggiornamento del cluster stesse, come consigliato dalle best practice.
Dopo aver preparato correttamente la VNet siamo passati alla configurazione del cluster, questo processo ha incluso la definizione di System Node, per ospitare i nodi di sistema che gestiscono le funzionalità essenziali, e User Node Pools per ospitare i carichi di lavoro. La seguente configurazione permette di ottimizzare l'allocazione delle risorse.
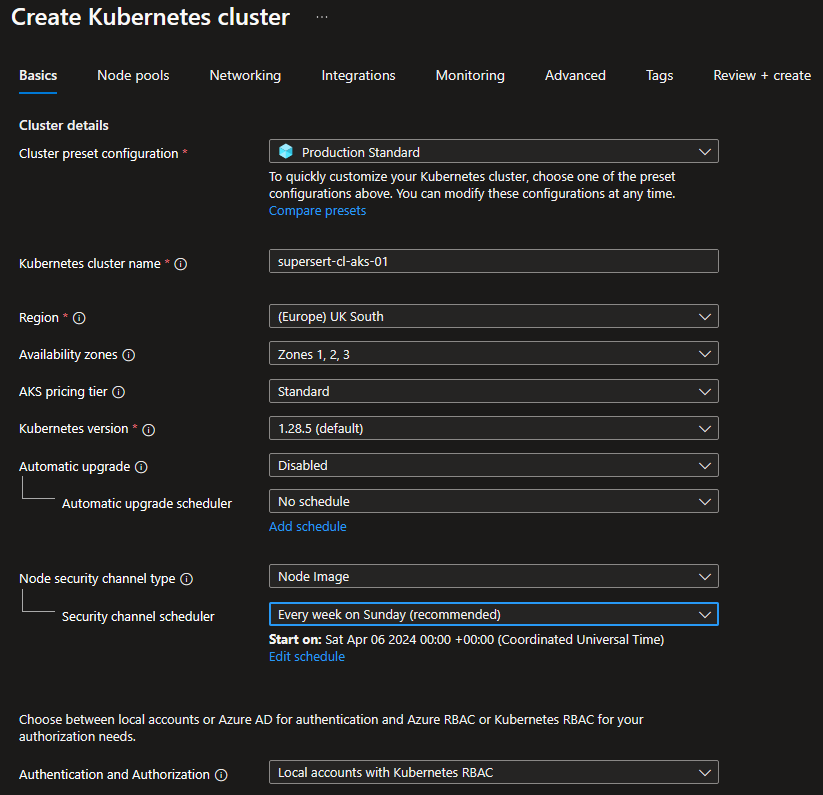
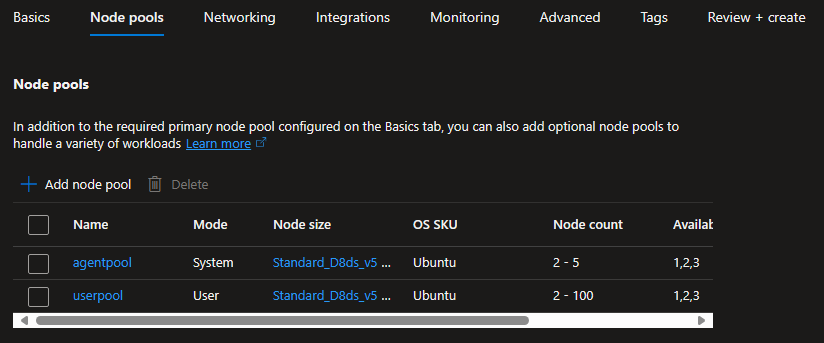
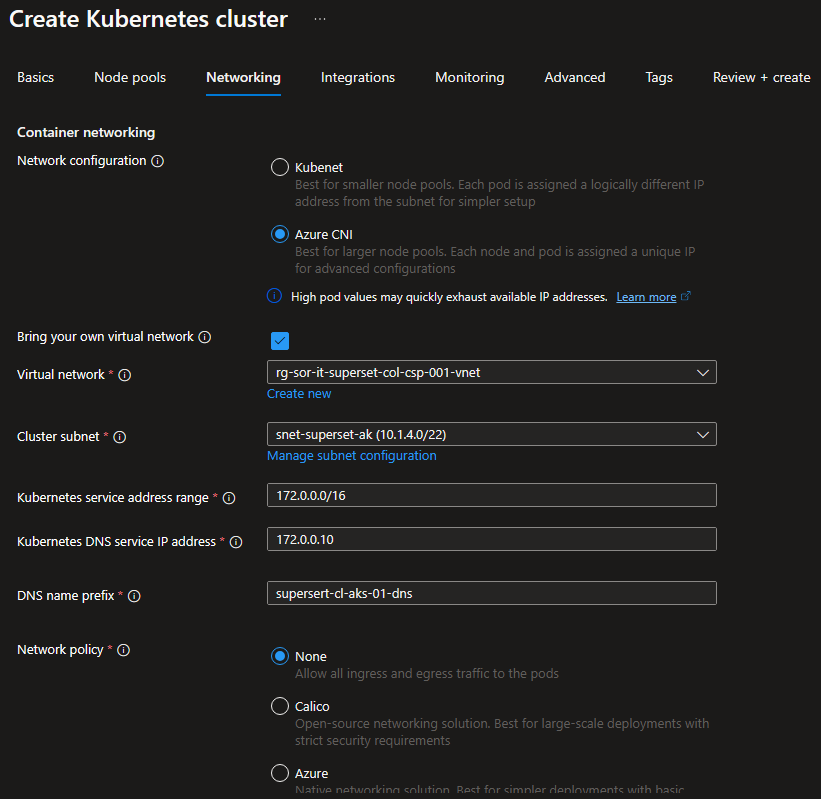
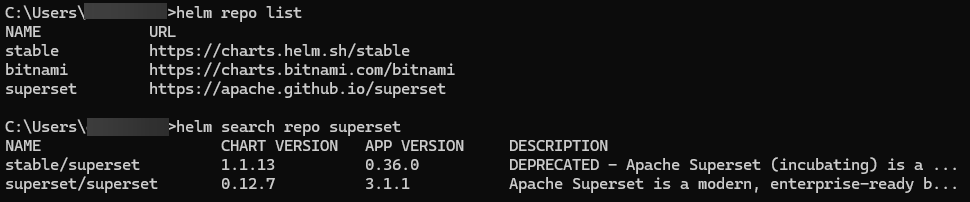
Per semplificare il processo di deployment abbiamo installato Helm e grazie ad una shell PowerShell sono stati lanciati i comandi per aggiungere il repository appropriato per accedere ai chart necessari per l'installazione di Apache Superset.

Sempre dalla command line, dopo aver eseguito il login in azure con comando az login, si è fatto il download delle credenziali necessarie per accedere al cluster attraverso il comando az aks get-credentials. Ottenuto e configurato il **context ** era possibile lanciare comandi kubectl sul cluster in cloud.
az login
az account list / show
az account set --subscription "id or name"
az aks get-credentials --resource-group "rg name" --name "aks cluster name" --overwrite-existing
Con i comandi kubectl config view e kubectl cluster-info è possibile recuperare informazioni sul contesto e sulla configurazione presenti all'interno del file .kube\config del profilo utente.

A questo punto abbiamo eseguito dei comandi di "test" per verificare il corretto collegamento:
- kubectl get deployments --all-namespaces=true
- kubectl get nodes
Volendo distribuire e separare l'applicazione di superset si è creato un namespace dedicato con il comando kubectl create namespace "ns name"
Ci siamo dedicati poi alla preparazione dei servizi PaaS necessari, come la cache Redis e il database, fondamentali in quanto rappresentano dipendenze per il funzionamento di Apache Superset.
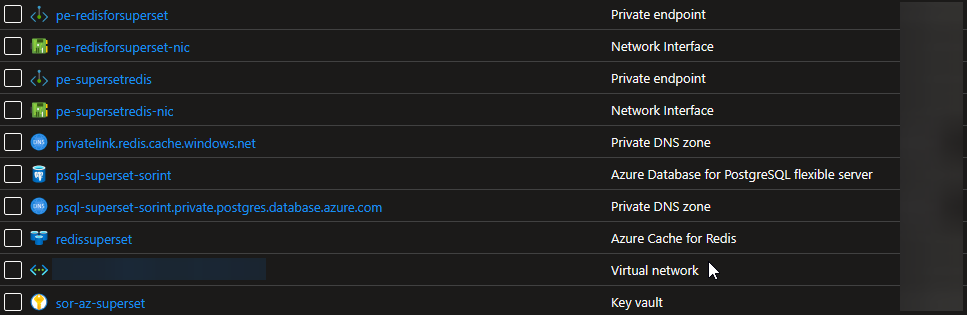
Per la Redis Cache, abbiamo configurato un Private Endpoint, una funzionalità di Azure che consente di garantire l'isolamento e la sicurezza assegnando al servizio una scheda di rete con indirizzamento privato, limitando l'accesso in inbound solo ai client autorizzati all'interno/esterno della VNet. Per quanto riguarda il database, si è fatta la VNet integration, collegando il servizio direttamente alla VNet, consentendo alle risorse di accedere al database tramite una connessione privata.
Eravamo pronti per procedere con la personalizzazione del file values.yaml del chart Helm per l'installazione di Apache Superset.
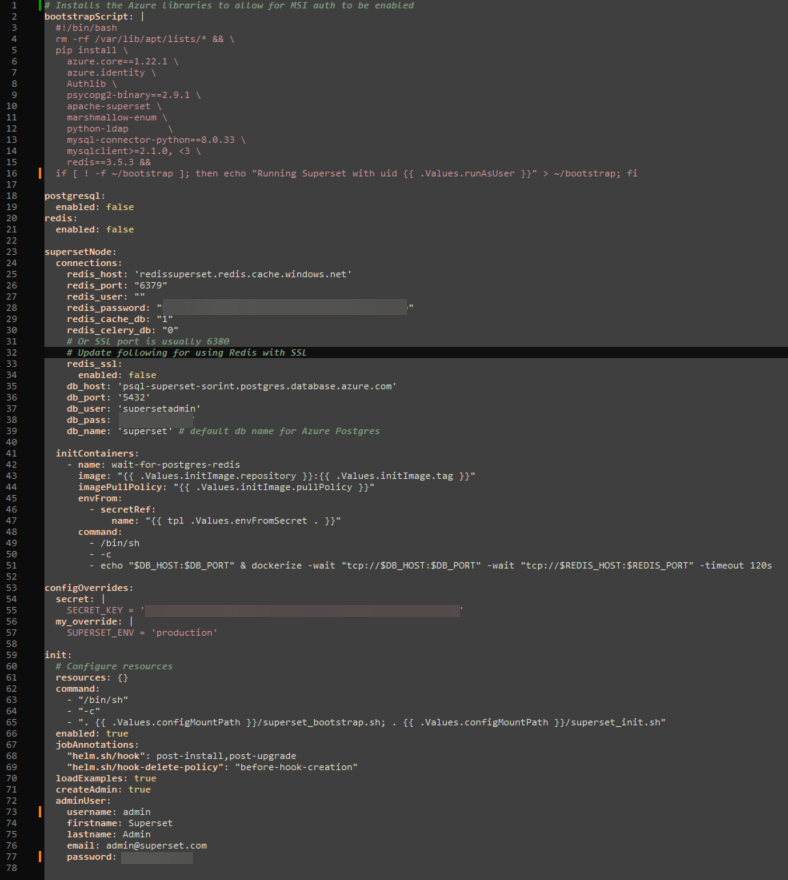
La configurazione del file helm ha previsto:
- modifica del bootstrap script per l'installazione delle librerie necessarie
- dichiarazione in false per redis e postesql in quanto i servizi erano esterni e non era necessario distribuire un pod per essi
- configurazione della connection al database e la cache redis
- l'init container è un tipo "speciale" di container che viene eseguito prima dei container principali, nell'esempio l'init container lancia un comando dockerize per verificare la connessione al database prima di far partire il pod di Apache Superset
- nella sezione config override abbiamo impostato la SECRET_KEY necessaria, altrimenti il pod non partirà con errore
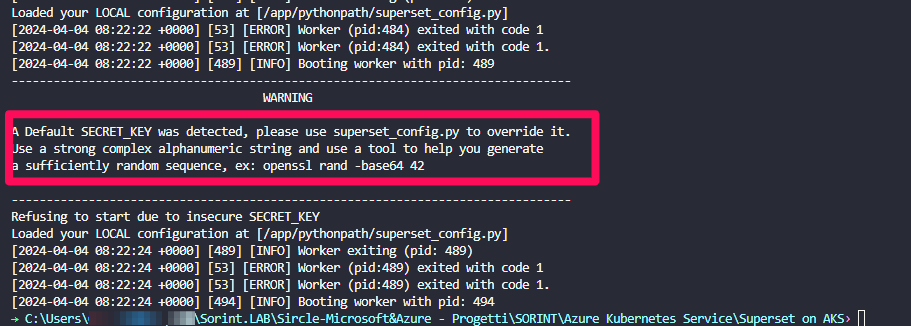
- su init invece abbiamo specificato l'utente amministratore che andava creato
Apache Superset infatti, una volta configurato richiede l'esecuzione di tre comandi (in questo caso automatizzati):
- superset fab create-admin
- superset db upgrade
- superset init
Finalmente possiamo lanciare l'installazione del chart con helm specificando il file values.yaml

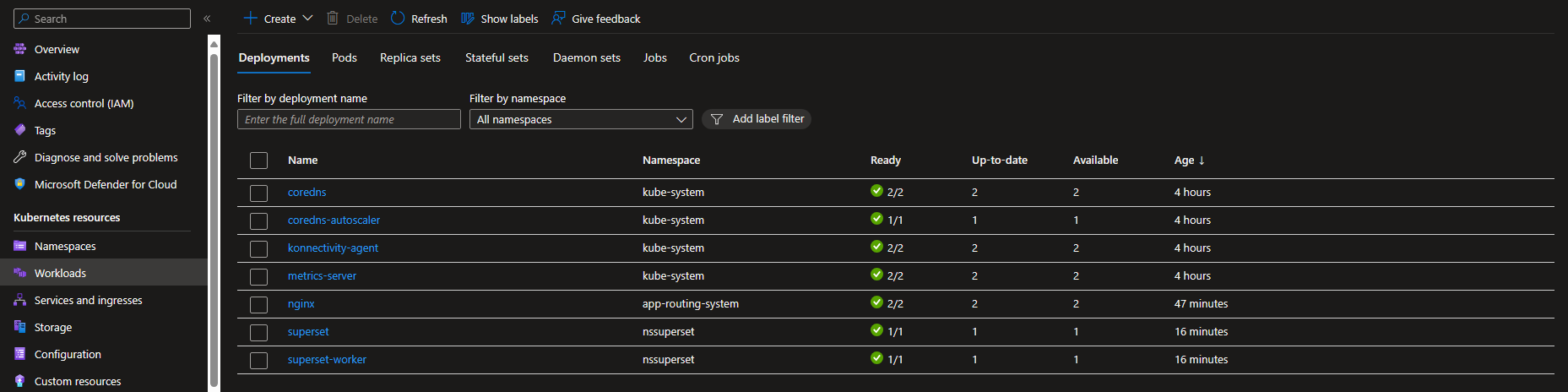
Dopo l'installazione, abbiamo verificato tramite il portale di Azure che tutto fosse up & running.

Con il comando kubectl logs è stata ottenuta una doppia conferma.
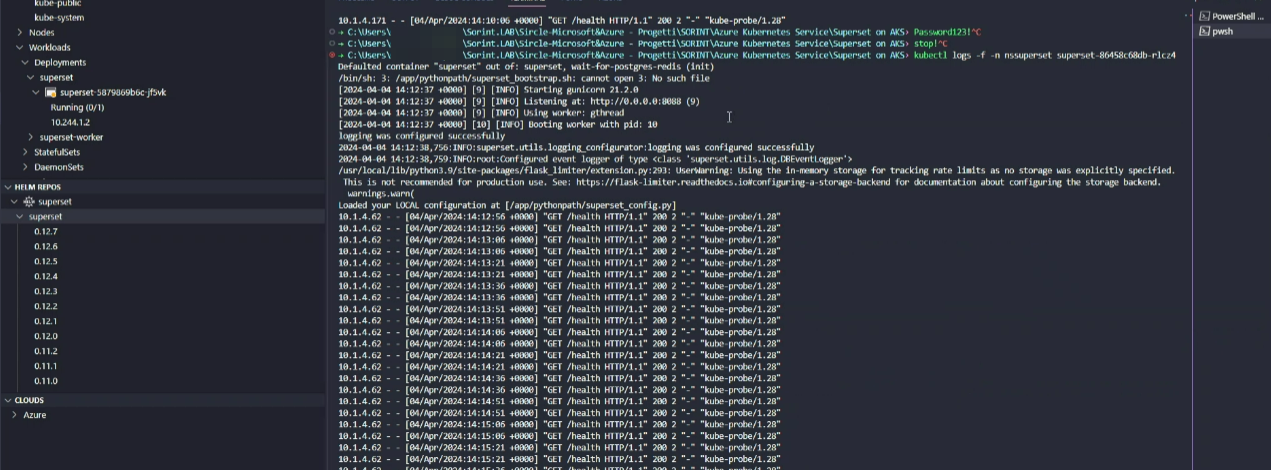

Il servizio Apache Superset di default è in ascolto sulla porta 8088, per accedervi è necessario esporre il servizio.
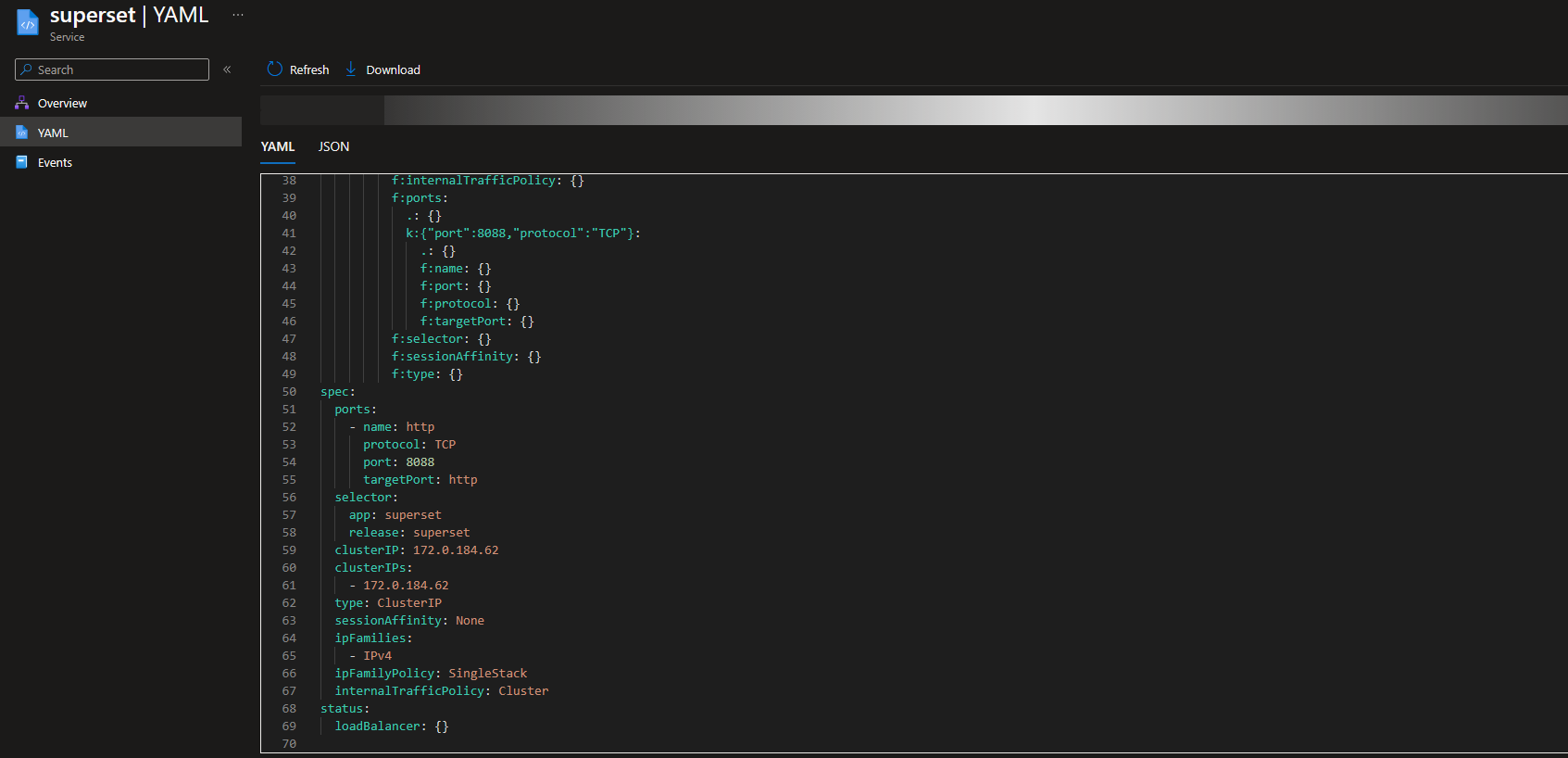
Puoi utilizzare diversi approcci, ma per un servizio HTTP come Apache Superset, la modalità consigliata è utilizzare un ingress. Grazie a questa configurazione, è possibile raggiungere l'interfaccia utente di Apache Superset dall'esterno del cluster.
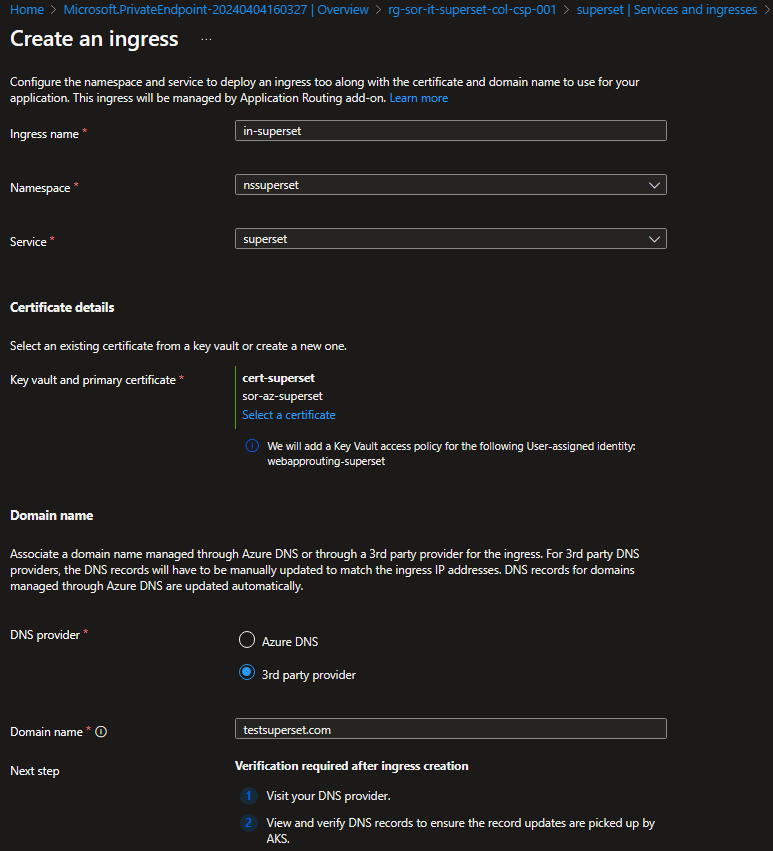
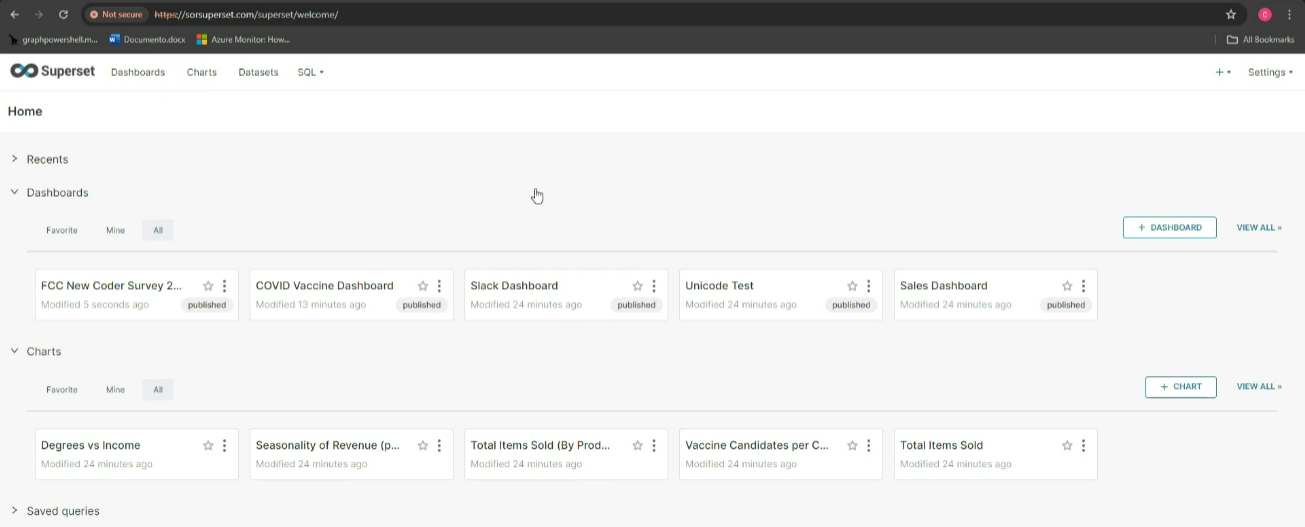
Con il collegamento alla pagina web possiamo affermare di aver completato con successo l'implementazione di Apache Superset su Kubernetes in ambiente Azure.
Riferimenti
- https://kubernetes.io/docs/concepts/overview/
- https://kubernetes.io/docs/reference/kubectl/
- https://learn.microsoft.com/en-us/azure/aks/intro-kubernetes
- https://learn.microsoft.com/en-us/azure/virtual-machine-scale-sets/overview
- https://learn.microsoft.com/en-us/azure/container-instances/
- https://superset.apache.org/docs/installation/running-on-kubernetes/
- https://helm.sh/docs/intro/
- https://yaml.org/

 Mohamed Msaad
Mohamed Msaad