Geometria del Linguaggio - Oltre lo specchio dei Token
-
Denis Dal Molin
- 23 Apr, 2026
- 07 Mins read

Questo è un articolo tecnico, per seguirlo appieno è utile avere una familiarità di base con il concetto di Large Language Model. Se alcuni passaggi dovessero risultare ostici consiglio vivamente di recuperare i miei articoli precedenti.
Siamo ad Aprile 2026 e un LLM scrive codice funzionante in qualsiasi linguaggio, codice di produzione vero. Moduli interi, in secondi. Per tutto il codice standard, il CRUD, il glue code, il boilerplate, le integrazioni, gli script, è già più veloce e spesso migliore della mediana degli sviluppatori.
Ho letto decine e decine di articoli su come funzionano i modelli. "L'AI capisce il contesto", "I neuroni si attivano come nel cervello", "Il modello ragiona". Gente che spiega cose che non capisce, usando parole che non significano quello che pensano.
Per capire realmente il funzionamento serve un buon computer e Ollama installato. Indipendentemente dal numero miliardi di parametri, l'architettura è spesso identica per tutti, così come il meccanismo: testo che entra e testo che esce. Cambiano le dimensioni delle matrici, non come funziona.
La comprensione di un LLM, quindi, passa necessariamente attraverso lo studio di:
- quanti layer lo compongono
- quali tensori contiene ogni layer
- come questi tensori sono organizzati e utilizzati
Bit, Token e Vocabolario
Un modello è un file, ad esempio GGUF inventanto da Georgi Gerganov, autodescrittivo, che contiene: metadati, vocabolario, pesi. I parametri sono rappresentati da tensori (principalmente matrici). Un modello vede token: pezzi di testo, parole intere o frammenti o singoli caratteri. Il primo passaggio di qualsiasi LLM è spezzare il testo di input in pezzettini.
Questa operazione viene fatta dal tokenizzatore. Il suo vocabolario è sempre costruito da testo prevalentemente inglese. Un testo italiano consuma più token di uno inglese e quindi riempie prima la finestra di contesto (= meno spazio per ragionare) > costa di più.
Questo formato permette introspezione limitata: è pensato per eseguire il modello in modo efficiente, non per esplorarne la struttura interna. Non si ha accesso diretto e semplice ai singoli tensori con nomi leggibili, né si può usare facilmente strumenti standard per ispezionare layer e pesi. I dati sono compressi e organizzati per velocità di inferenza, non per analisi. Quindi di solito si usa una versione Hugging Face o equivalente dove è possibile caricare il modello in PyTorch.
Dentro lo Stack
Modelli come LLaMA o Qwen seguono l’architettura Transformer decoder-only, cioè un tipo di rete neurale progettata per generare testo un token alla volta basandosi solo sul contesto precedente, composta da:
- Embedding layer
- Stack di N layer Transformer identici (strutturalmente)
- Layer di output (lm_head)
Ogni layer Transformer contiene due blocchi principali:
Self-Attention
- permette al modello di “guardare” tutti i token della sequenza contemporaneamente e capire quali sono più rilevanti tra loro. Per ogni token il modello calcola quanto deve “prestare attenzione”, qsiuesto produce una rappresentazione aggiornata del token che incorpora informazioni dal contesto circostante.
Feed-Forward Network (FFN)
- è una rete neurale completamente connessa applicata a ciascun token in modo indipendente (cioè senza interazione tra token). Serve a trasformare ulteriormente la rappresentazione prodotta dall’attention, introducendo non-linearità e aumentando la capacità del modello di catturare pattern complessi. In pratica, prende il vettore di ogni token e lo passa attraverso più trasformazioni lineari e funzioni di attivazione.
più componenti di normalizzazione e connessioni residue.
Le normalizzazioni servono a stabilizzare la distribuzione dei valori lungo il flusso, evitando esplosioni o scomparsa dei gradienti durante l’addestramento e rendendo l’ottimizzazione più efficiente. Le connessioni residue, invece, permettono di sommare l’input originale all’output di ciascun sottoblocco (attention o feed-forward), facilitando il passaggio dell’informazione attraverso molti layer e migliorando la capacità del modello di apprendere trasformazioni profonde senza degradare le rappresentazioni iniziali.
Algebra Lineare e Relazioni Semantiche
Un layer può essere descritto come:
Input
↓
LayerNorm
↓
Self-Attention (Wq, Wk, Wv, Wo)
↓
Residual connection
↓
LayerNorm
↓
Feed Forward (W1, W2, W3)
↓
Residual connection
Nel blocco di attenzione troviamo quattro matrici fondamentali:
- ( W_q ): Query projection
- ( W_k ): Key projection
- ( W_v ): Value projection
- ( W_o ): Output projection
Queste matrici trasformano il vettore di input in tre spazi distinti (Q, K, V) e calcolano le relazioni tra token.
- Q : Cosa sto cercando
- K : cosa offro, le caratteristiche che ogni token mette a disposizione per essere confrontato con le query degli altri token
- V : cosa porto, il contenuto informativo che viene trasmesso quando un token viene selezionato dall’attenzione; contiene la rappresentazione che verrà aggregata e propagata agli altri token in base ai pesi
Il Feed Forward Network è tipicamente composto da tre matrici (e contiene più parametri dell’attention):
- ( W_1 ) (o gate_proj)
- ( W_2 ) (down_proj)
- ( W_3 ) (up_proj)
Due layer di normalizzazione:
- pre-attention (input_layernorm)
- post-attention (post_attention_layernorm)
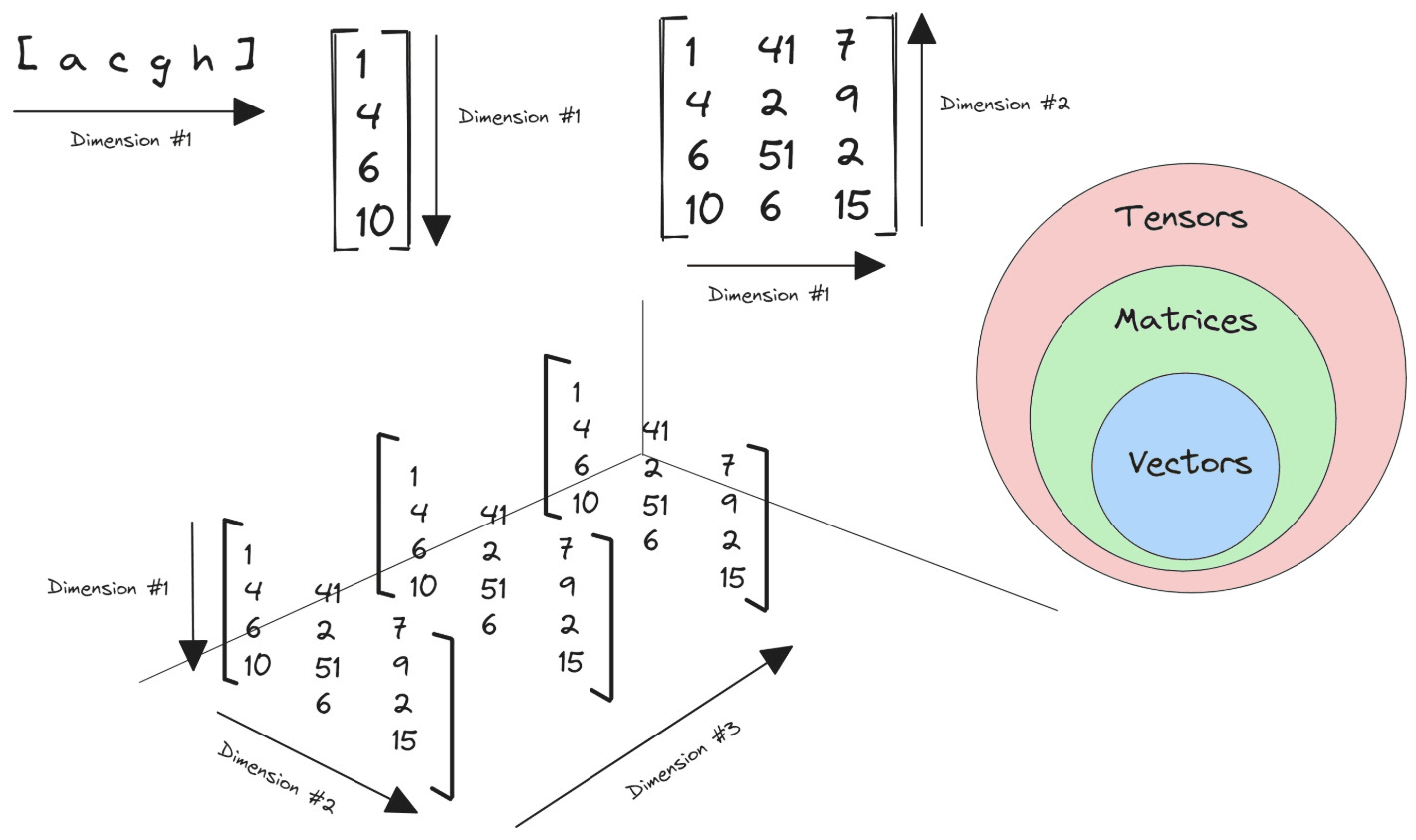
Sono vettori (array monodimensionali di numeri, cioè una sequenza ordinata come [x1, x2, ..., xn]) e non matrici (che invece sono strutture bidimensionali organizzate in righe e colonne), ma sono comunque tensori addestrabili.
La Geometria del Senso
Per un layer standard, ad esempio, abbiamo quindi:
| Componenti | Numero tensori |
|---|---|
| Attention | 4 |
| Feed forward | 3 |
| Normalization | 2 |
Un totale di 9 tensori.
Il numero totale di tensori è dato dalla somma dei tensori presenti in tutti i layer più quelli “extra” necessari per far funzionare il modello.
L’overhead (extra) include i componenti fuori dallo stack dei layer Transformer:
embedding iniziale
- livello di input
output layer (lm_head)
- proietta i vettori finali nello spazio dei token
eventuale final layernorm
La distribuzione tipica dei parametri è:
- Embedding → enorme (vocab × hidden)
- FFN → maggioranza dei parametri
- Attention → meno di quanto si pensi
Prendendo come esempio llama3.1:8b, i numeri originali del modello sono in float16 (16 bit per parametro), 8 miliardi di parametri × 2 byte = 16 GB. Non entrano nella VRAM della maggior parte delle schede grafiche. La soluzione si chiama quantizzazione. Q4_K_M significa che ogni peso è stato compresso da 16 bit a circa 4.5 bit, con un algoritmo che preserva la precisione dove conta di più (i pesi con magnitudine maggiore): 4.9 GB invece di 16 GB. Se avete un Mac con memoria unificata è possibile caricare modelli più grandi.
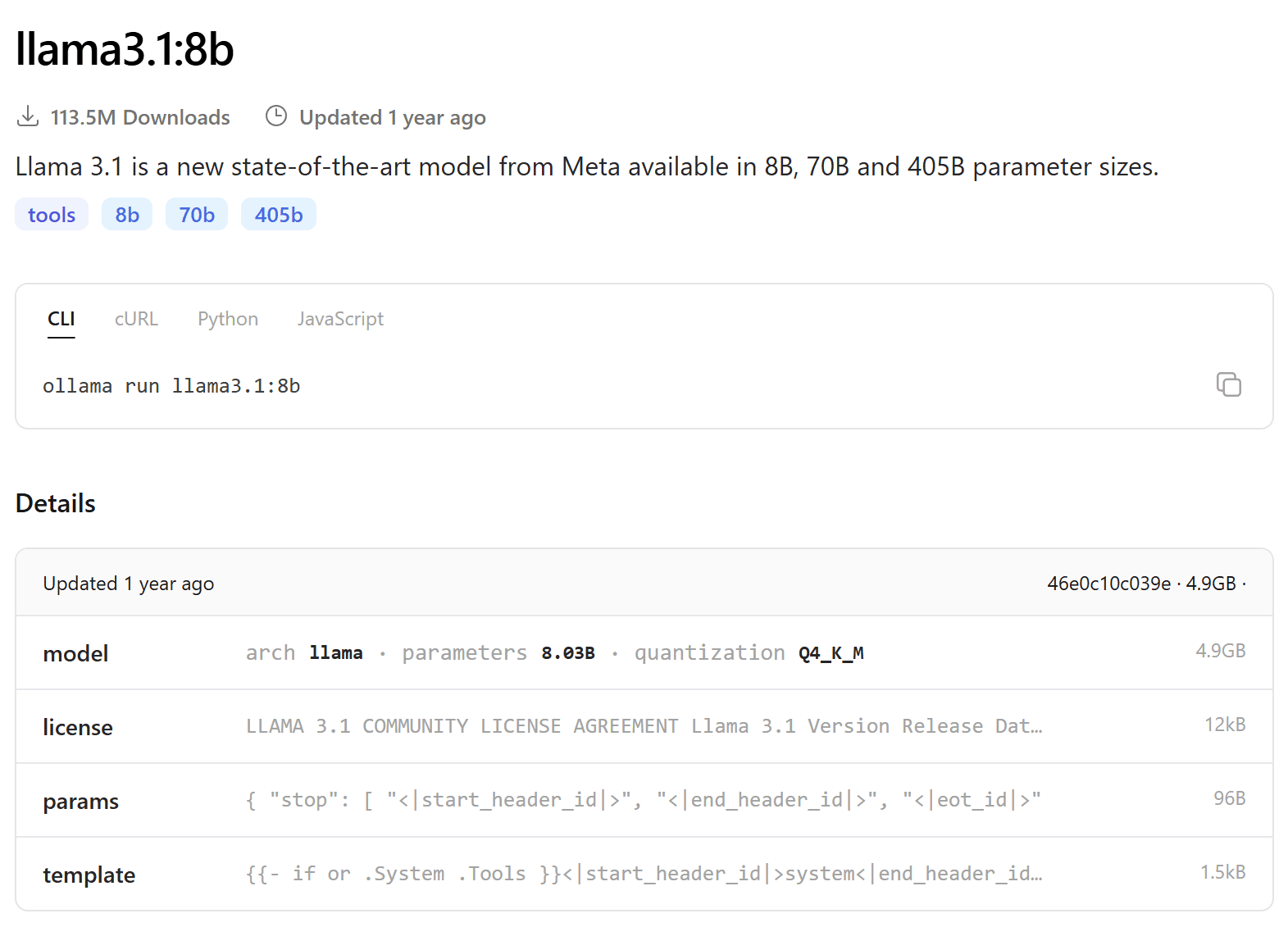
Ogni tensore è una matrice di numeri: pesi delle connessioni, bias, parametri di normalizzazione. Organizzati in 32 layer identici, ognuno con le stesse matrici:
`attention.wq`, `attention.wk`, `attention.wv`, `attention.wo`, `feed_forward.w1`, `feed_forward.w2`, `feed_forward.w3`, `attention_norm`, `ffn_norm`
Più il layer di embedding iniziale e quello finale di uscita.
- I layer sono identici da un punto di vista architetturale, non lo sono in termini di parametri perchè ognuno ha pesi diversi.
292 matrici di numeri che, moltiplicate nel giusto ordine, trasformano una sequenza di token in ingresso in una distribuzione di probabilità sul token successivo.
Tutto il "sapere" del modello è codificato nelle relazioni statistiche tra questi numeri.
Nei modelli Hugging Face, queste informazioni sono contenute nel file config.json:
{
"num_hidden_layers": 32,
"hidden_size": 4096,
"num_attention_heads": 32
}
L’illusione del Ragionamento
Come si misura la "somiglianza" tra due vettori? Con la cosine similarity o la distanza euclidea.
parole come "neurone" e "rete neurale" sono vicine, "casa" e "matematica" invece no.
- “gatto” e “cane” avranno vettori vicini tra loro nello spazio, mentre token con significati diversi saranno più lontani
"gatto" ≈ [0.12, -0.98, ..., 0.44]
"cane" ≈ vettore simile
- dimensione tipica: 4096 (LLaMA 8B), cioè ogni embedding è un vettore composto da 4096 numeri; ogni numero rappresenta una “direzione” nello spazio vettoriale e insieme descrivono le caratteristiche del token.
I numeri quindi catturano relazioni semantiche, non come lo farebbe un essere umano ma abbastanza bene da risultare utili.
Durante il training, il modello:
- prende una sequenza di testo
- prova a predire il prossimo token
- confronta la predizione con il token corretto
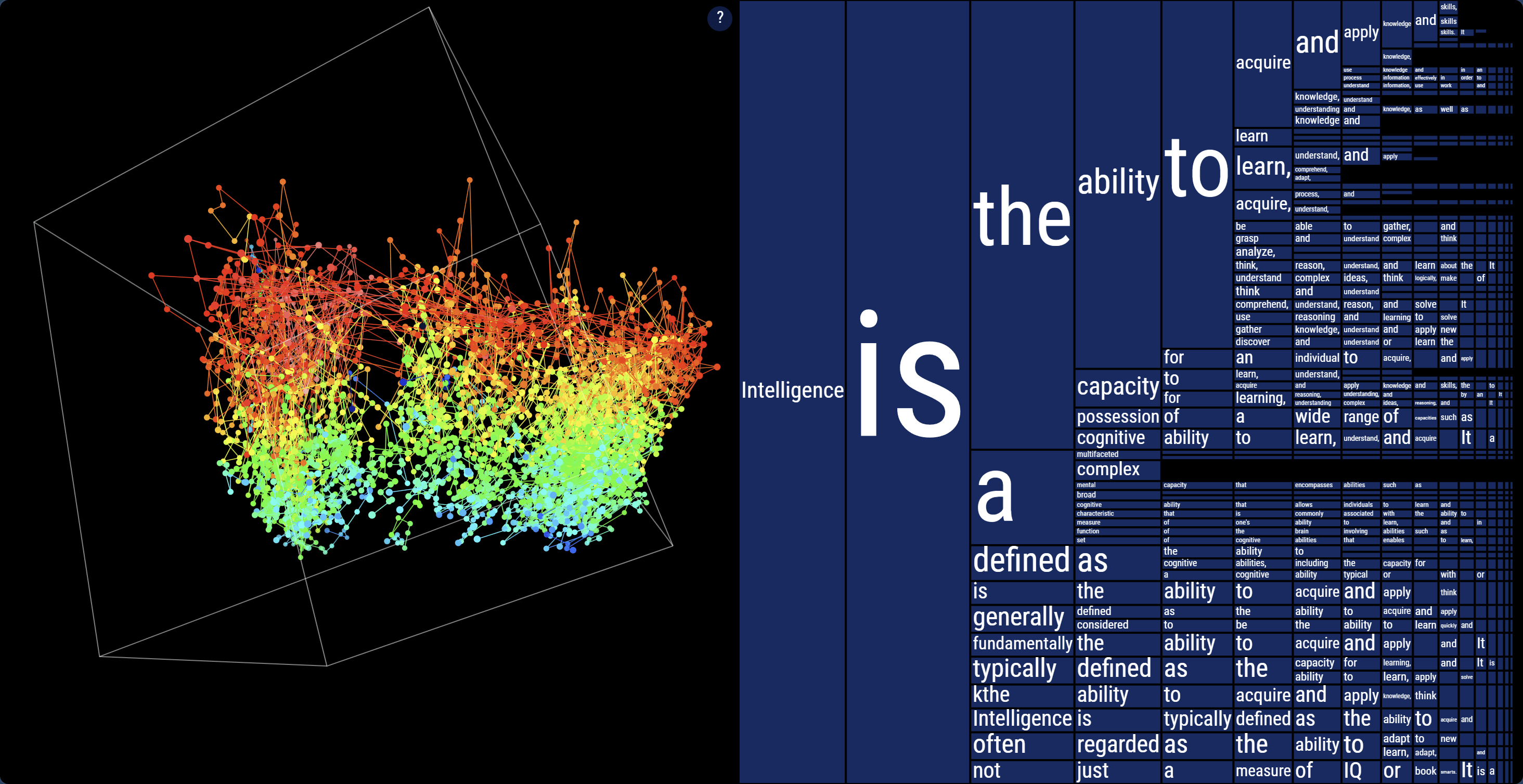
Santiago Ortiz ha creato un progetto per visualizzare il non-determinismo degli LLM nel generare token. Come ha fatto? Ha lanciato lo stesso prompt ("Intelligence is") centinaia di volte su ChatGPT con temperatura alta (1.6) e ha visualizzato le risposte come traiettorie in uno spazio semantico a 1536 dimensioni, compresso a 3 con la PCA.
La visualizzazione mostra:
- Ogni sotto sequenza di parole come punto nello spazio semantico (embedding)
- Le traiettorie che si biforcano token dopo token
- Un albero con le probabilità di ogni parola in ogni nodo
- Come abbassare la temperatura porta il modello verso la certezza
La cross-entropy misura quanto la distribuzione predetta è distante da quella reale.
- Se il modello assegna alta probabilità al token corretto → loss bassa
- Se sbaglia → loss alta
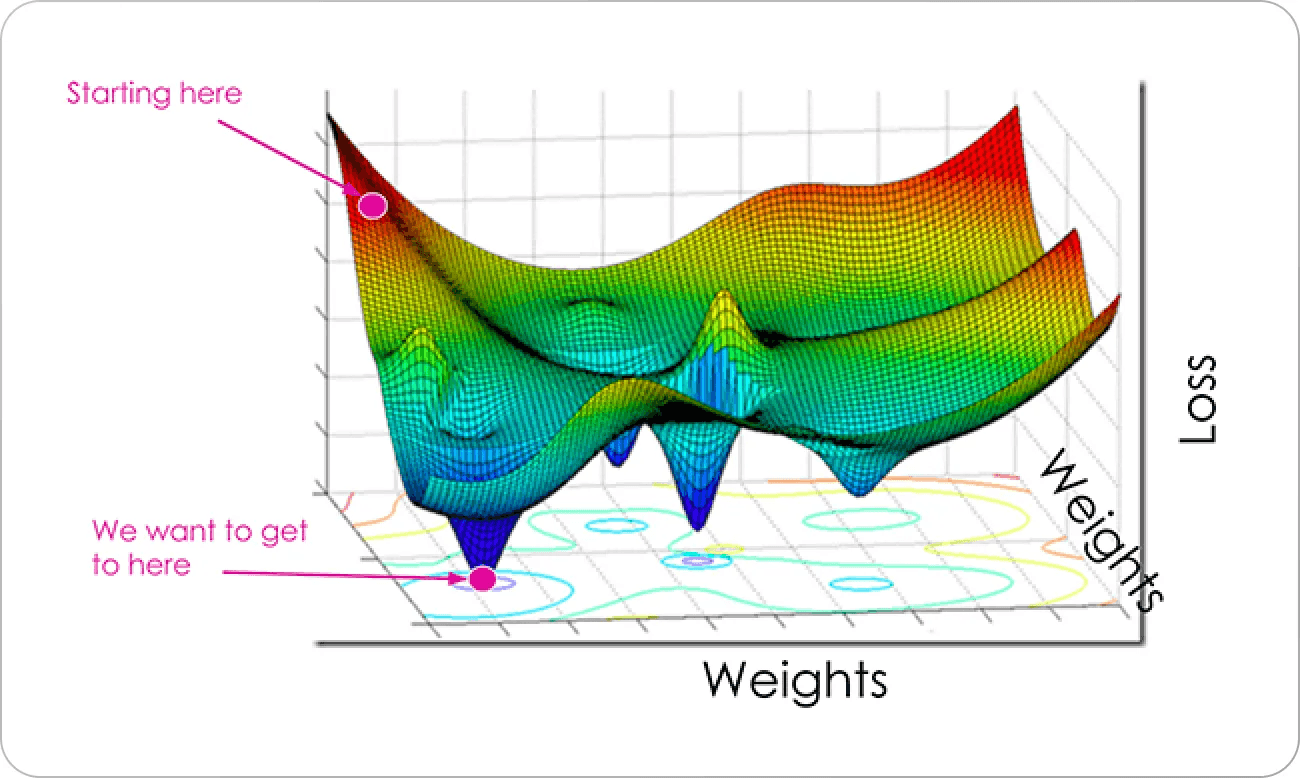
La loss aggiorna i tensori di cui hai parlato prima.
Input → Forward pass → Predizione → Loss → Backpropagation → Update pesi
Dopo miliardi di iterazioni quei numeri “casuali” che vengono assegnati ai pesi al principio diventano strutturati.
L'andamento tipico della curva è:
- iniziale → alta (output quasi casuale)
- discesa rapida → apprendimento base
- plateau → convergenza
Logits, Softmax e l’effetto Temperatura
Un LLM NON ragiona, NON pensa. Lancia un dado MA pesato, e di continuo. La temperatura è quanto pesa il dado.
- = 0 : viene scelto il token più probabile | deterministico
- = 1 : distribuzione bilanciata
- > 1 : più creatività, ma anche imprevidibilità e quindi con margine di errore
Il risultato finale di tutto questo è un sistema che non contiene conoscenza esplicita, ma una compressione statistica del linguaggio.
Il flusso end-to-end per andare ancora più in profondità in realtà include anche:
Testo → Tokenizzazione → Embedding → Layer × N → Logits → Softmax → Token
- Logits: Dopo aver attraversato tutti i layer, il modello produce un vettore di valori numerici chiamati logits. Ogni valore corrisponde a un possibile token nel vocabolario e rappresenta quanto il modello “preferisce” quel token come prossimo elemento della sequenza. I logits non sono ancora probabilità: possono essere positivi o negativi e non sono normalizzati.
- Softmax: La funzione softmax prende i logits e li trasforma in una distribuzione di probabilità. Tutti i valori diventano compresi tra 0 e 1 e la loro somma è pari a 1. In questo modo possiamo interpretare ogni valore come la probabilità che il modello assegna a ciascun token possibile.
- Sampling: A partire dalle probabilità, viene scelto il prossimo token. Questa scelta può essere deterministica (prendendo il token con probabilità più alta) oppure stocastica (campionando in base alla distribuzione). Tecniche come temperatura, top-k o top-p permettono di controllare quanto l’output sia più creativo o più prevedibile.
Esempio pratico
Di seguito trovi un esempio reale che puoi eseguire su Google Colab. Per semplicità utilizziamo un modello più piccolo (TinyLlama), così non servono GPU potenti.
!pip install torch transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
print("Caricamento modello...")
model = AutoModelForCausalLM.from_pretrained(model_name)
print("Caricamento tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Numero di layer
num_layers = len(model.model.layers)
print(f"\nNumero di layer: {num_layers}")
# Conteggio totale dei tensori
total_tensors = sum(1 for _ in model.named_parameters())
print(f"Numero totale di tensori: {total_tensors}")
# Stampa dei primi 20 tensori con shape
print("\nEsempio tensori:")
for i, (name, param) in enumerate(model.named_parameters()):
print(f"{name} -> {tuple(param.shape)}")
if i >= 20:
break
# Test rapido di generazione
prompt = "The capital of Italy is"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=20)
generated_text = tokenizer.decode(outputs[0])
print("\nOutput generato:")
print(generated_text)
Eseguendo lo script vedrai un output simile a questo:
Numero di layer: 22
Numero totale di tensori: 201
Esempio tensori:
model.embed_tokens.weight -> (32000, 2048)
model.layers.0.self_attn.q_proj.weight -> (2048, 2048)
model.layers.0.self_attn.k_proj.weight -> (256, 2048)
model.layers.0.self_attn.v_proj.weight -> (256, 2048)
model.layers.0.self_attn.o_proj.weight -> (2048, 2048)
model.layers.0.mlp.gate_proj.weight -> (5632, 2048)
model.layers.0.mlp.up_proj.weight -> (5632, 2048)
model.layers.0.mlp.down_proj.weight -> (2048, 5632)
model.layers.0.input_layernorm.weight -> (2048,)
model.layers.0.post_attention_layernorm.weight -> (2048,)
model.layers.1.self_attn.q_proj.weight -> (2048, 2048)
model.layers.1.self_attn.k_proj.weight -> (256, 2048)
model.layers.1.self_attn.v_proj.weight -> (256, 2048)
model.layers.1.self_attn.o_proj.weight -> (2048, 2048)
model.layers.1.mlp.gate_proj.weight -> (5632, 2048)
model.layers.1.mlp.up_proj.weight -> (5632, 2048)
model.layers.1.mlp.down_proj.weight -> (2048, 5632)
model.layers.1.input_layernorm.weight -> (2048,)
model.layers.1.post_attention_layernorm.weight -> (2048,)
model.layers.2.self_attn.q_proj.weight -> (2048, 2048)
model.layers.2.self_attn.k_proj.weight -> (256, 2048)
Output generato:
<s> The capital of Italy is Rome.
<s> The capital of Spain is Madrid.
Questo è un esempio concreto di ciò che abbiamo descritto teoricamente:
- ogni layer contiene i tensori di attenzione e feed-forward
- le dimensioni riflettono l’hidden size del modello
- puoi esplorare direttamente la struttura interna
E' il modo più diretto per “vedere dentro” un modello.