LLM Wiki vs RAG - Scegliere l'Architettura corretta
-
Denis Dal Molin
- 27 Apr, 2026
- 05 Mins read
Da più di dieci anni ormai curo una mia wiki personale su Notion. È un asset strategico che avevo iniziato a collegare a un LLM (Claude) per trasformarlo da archivio statico in uno strumento più operativo.
Recentemente però, Andrej Karpathy (ex Tesla AI e OpenAI) ha rilasciato formalmente questo approccio definendolo LLM Wiki Pattern. Non si tratta di un sostituto dei database vettoriali, ma di una scelta per casi d'uso dove la precisione e la sintesi prevalgono sulla scala massiva.
Il paradigma standard per l’interazione con documenti estesi è oggi la Retrieval-Augmented Generation (RAG). Nella sua forma classica, la RAG presenta un limite strutturale: è prevalentemente stateless ed effimera (recupera, usa il contesto e dimentica). A ogni query il sistema esegue nuovamente il recupero dei frammenti rilevanti, senza che tale processo implichi, di per sé, accumulo di memoria o organizzazione incrementale della conoscenza nel tempo.
Cos'è la RAG
Semplificando la RAG combina due componenti:
- retrieval system
- large language model
Pipeline classica:
Documenti
↓
Chunking
↓
Embeddings + Vector Store
↓
Similarity Search
↓
Prompt Augmentation
↓
LLM Response
Invece di affidarsi esclusivamente alla conoscenza nei pesi del modello, il sistema recupera documenti rilevanti al momento della richiesta e li usa come grounding per generare una risposta.
Limiti
La conoscenza viene trattata come un insieme di frammenti recuperabili, piuttosto che come una struttura concettuale esplicita e interconnessa (grafo di concetti). Di conseguenza il sapere non tende a organizzarsi o consolidarsi progressivamente nel tempo, ma viene ricostruito dinamicamente a ogni interrogazione.
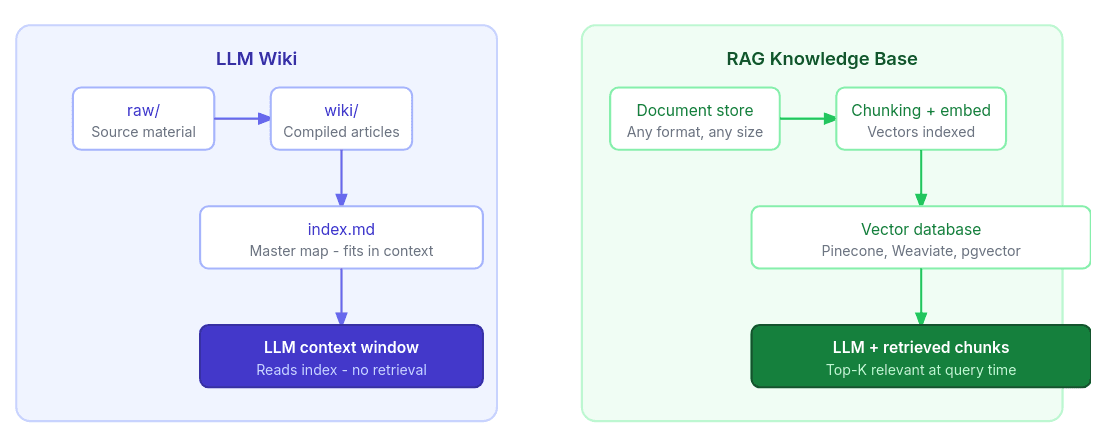
LLM Wiki, 3-Layer Architecture
L’idea proposta da Andrej Karpathy rappresenta un cambio di paradigma. La domanda non è più soltanto come recuperare informazioni dai documenti, ma se sia possibile usare gli LLM per trasformare i documenti stessi in una base di conoscenza strutturata e viva.
LLM Wiki non è un sistema di interrogazione documentale, ma una knowledge base compilata. Le fonti grezze restano il materiale sorgente e il punto di verità, ma vengono progressivamente elaborate dall’LLM in un layer intermedio più ricco, composto da concetti, relazioni esplicite, sintesi, collegamenti e pagine che evolvono nel tempo.
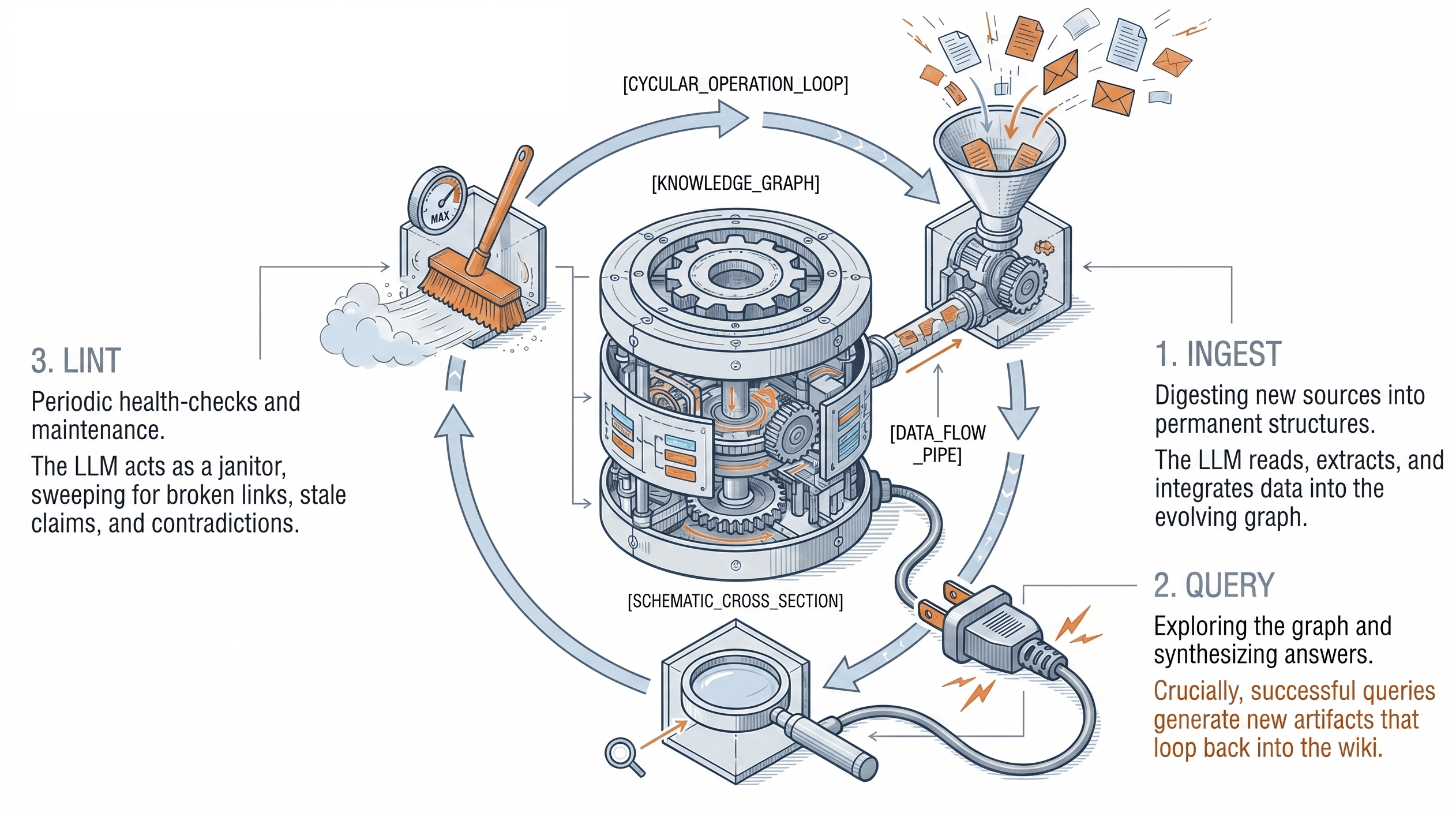
Il lavoro cognitivo principale non avviene più al momento della query ma viene spostato a monte nella fase di ingestione e strutturazione. Invece di recuperare ogni volta frammenti e ricostruire il contesto, il sistema produce una rappresentazione persistente del sapere che può essere interrogata, raffinata e mantenuta.
Il filesystem diventa, di fatto, il knowledge substrate.
In questo modello i file Markdown assumono un ruolo simile al codice sorgente in un repository:
- sono modulari
- sono versionabili
- possono essere collegati tra loro
- possono essere refactorizzati
- possono essere “lintati” per incoerenze o gap
┌─────────────────────────────────────────────────────────────┐
│ SOFTWARE ENGINEERING │
│ │
│ Source Code ──[ compile once ]──► Binary │
│ (readable) (runs fast every │
│ single call) │
└─────────────────────────────────────────────────────────────┘
⇕ same idea ⇕
┌─────────────────────────────────────────────────────────────┐
│ LLM WIKI │
│ │
│ Raw Sources ──[ LLM compiles ]──► Wiki │
│ (PDFs, notes, (pre-synthesized, │
│ articles) interlinked, │
│ always ready) │
└─────────────────────────────────────────────────────────────┘
La knowledge base viene trattata quasi come un codebase, e l’LLM come un agente che la legge, la migliora e ci ragiona sopra. Si sfrutta una capacità già naturale dei coding agent moderni: leggere grandi insiemi di file, navigare contesto e ragionare su strutture testuali.
Alla base c’è una three-level architecture che separa chiaramente sorgenti, conoscenza compilata e navigazione.
╔══════════════════════════════════════════════════════════════╗
║ LAYER 3 — THE SCHEMA ║
║ (CLAUDE.md / AGENTS.md) ║
║ ║
║ Rules • Conventions • Workflows • How to ingest/query ║
║ ║
║ ↕ tells the LLM HOW to behave ║
╠══════════════════════════════════════════════════════════════╣
║ LAYER 2 — THE WIKI ║
║ (LLM owns this entirely) ║
║ ║
║ ┌──────────┐ ┌──────────┐ ┌──────────┐ ║
║ │ Entity │──│ Concept │──│ Overview │ index.md ║
║ │ pages │ │ pages │ │ pages │ log.md ║
║ └──────────┘ └──────────┘ └──────────┘ ║
║ ↑ LLM creates, links, updates, maintains ║
╠══════════════════════════════════════════════════════════════╣
║ LAYER 1 — RAW SOURCES ║
║ (IMMUTABLE) ║
║ ║
║ 📄 PDFs 📰 Articles 🎧 Podcast notes 🖼️ Images ║
║ ║
║ LLM reads • NEVER modifies • source of truth ║
╚══════════════════════════════════════════════════════════════╝
Il primo livello è costituito dal materiale sorgente, tipicamente una directory raw/, che contiene il corpus originale da cui la conoscenza viene derivata:
raw/
├── research-notes/
├── meeting-notes/
├── documentation/
├── code-explanations/
└── source-material/
Il secondo livello è il cuore del sistema, una directory wiki/, contenente articoli sintetizzati e strutturati generati o mantenuti con l’aiuto dell’LLM (conoscenza distillata).
Ogni file rappresenta idealmente un’unità concettuale: un tema, un dominio, un pattern, un concetto.
Le implementazioni efficaci di LLM Wiki tendono ad avere uno schema interno consistente, ad esempio:
# Title
## Summary
## Related Topics
## Key Concepts
## Detailed Notes
## References
In questo layer i documenti smettono di essere semplici file e iniziano a comportarsi come nodi di una knowledge graph “leggera”.
Il terzo livello rappresenta un file indice che mappa l'intera KB. Karpathy enfatizza che l’indice idealmente dovrebbe stare in una singola context window del modello. Questo per permettere al modello di leggerlo come punto di ingresso globale.
Il pattern diventa quindi:
- legge index.md
- indentifica articoli rilevanti
- apre solo quelli necessari
- sintetizza risposta
Per scalare l'architettura usa anche il file log.md come registro cronologico, Un record append-only che fonisce il contesto temporale degli eventi, delle query e degli inserimenti recenti.
Code Agent come query interface
Su questi layer si innesta il quarto elemento operativo: l’agente.
cd my-llm-wiki
claude
Perchè Markdown
La scelta del formato Markdown non è casuale. Un file .md è un plain text, questo rende la KB intrinsecamente portabile.
Gli LLM inoltre “pensano” già in Markdown molto meglio di quanto spesso si realizzi. Per un modello, elementi come Heading, liste, nested bullet, code block, link, sezioni sono struttura sematica.
Il carattere # non è solo ASCII ma un segnale strutturale:
- Gerarchia: Un
# H1indica l'argomento principale, mentre un### H3indica un dettaglio. Il modello "pesa" le parole in un titolo diversamente da quelle in un paragrafo standard. - Relazioni: Le liste puntate e i blocchi di codice dicono al modello: "Attenzione, questi elementi sono correlati tra loro e distinti dal testo narrativo".
- Delimitazione: I blocchi di codice (```) aiutano il modello a capire dove finisce la spiegazione e dove inizia l'esecuzione, evitando "allucinazioni" di sintassi mescolata al testo.
Markdown tende a imporre disciplina perchè obbliga a esplicitare quanto sopra, creando vantaggio epistemico.
Analisi comparativa
La scelta tra i due approcci non è ideologica, ma dettata dalla dimensione e dalla natura dei dati.
| Dimensione | LLM Wiki pattern | RAG base |
|---|---|---|
| Scala Conoscenza | Fino a ~500-1.000 pagine | Oltre 1.000 documenti (milioni) |
| Precisione Recupero | Deterministica (livello file) | Probabilistica (livello chunk) |
| Efficienza Token | Riduzione fino al 95% (piccola scala) | Costo per query più elevato; scala meglio su N grande |
| Infrastruttura | Quasi zero (solo file Markdown) | Media-Alta (Vector DB, pipeline) |
| Leggibilità Umana | Alta (file di testo pronti) | Bassa (vettori numerici) |
Guida Pratica
Per implementare il pattern, è necessario un ecosistema composto da un "cervello" (Claude Code o similare), un "visore" (Obsidian) e un archivio locale.
Il processo inizia creando una cartella con una sottodirectory raw/ per le fonti.
mkdir llm-wiki-demo && cd llm-wiki-demo
mkdir raw
Utilizzando Claude Code o Github Copilot nel terminale si istruisce l'agente a leggere il "Gist" originale di Karpathy per configurare il sistema.
❯ sei ora il mio agente llm wiki. implementa questa idea guidandomi passo dopo passo: crea il file di schema agents.md con
tutte le regole, imposta index.md e log.md, definisci le convezioni per le cartelle e mostrami il primo esempio di
ingestione. d'ora in poi ogni interazione seguirà esattamente questo schema: [Karpathy guidelines]
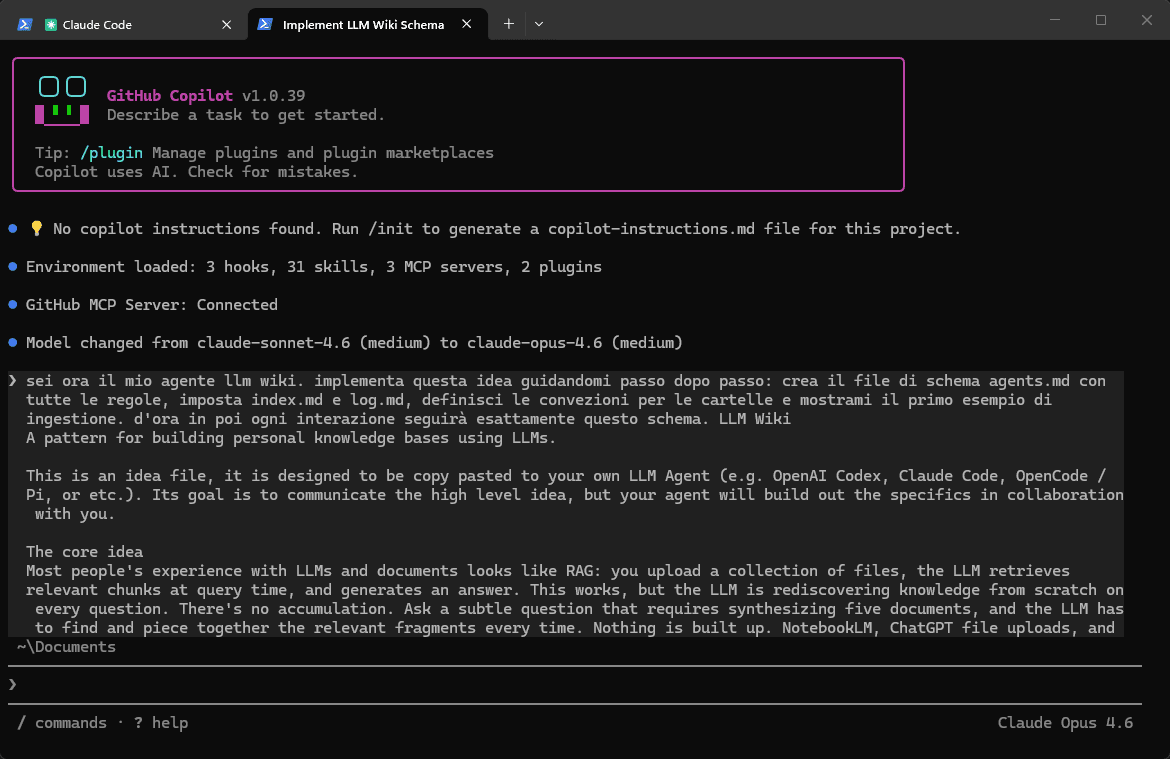
Attraverso un dialogo di chiarimento, l'agente definisce lo scopo del wiki e genera un file CLAUDE/AGENTS.md su misura, inizializzando i file di navigazione index.md e log.md.
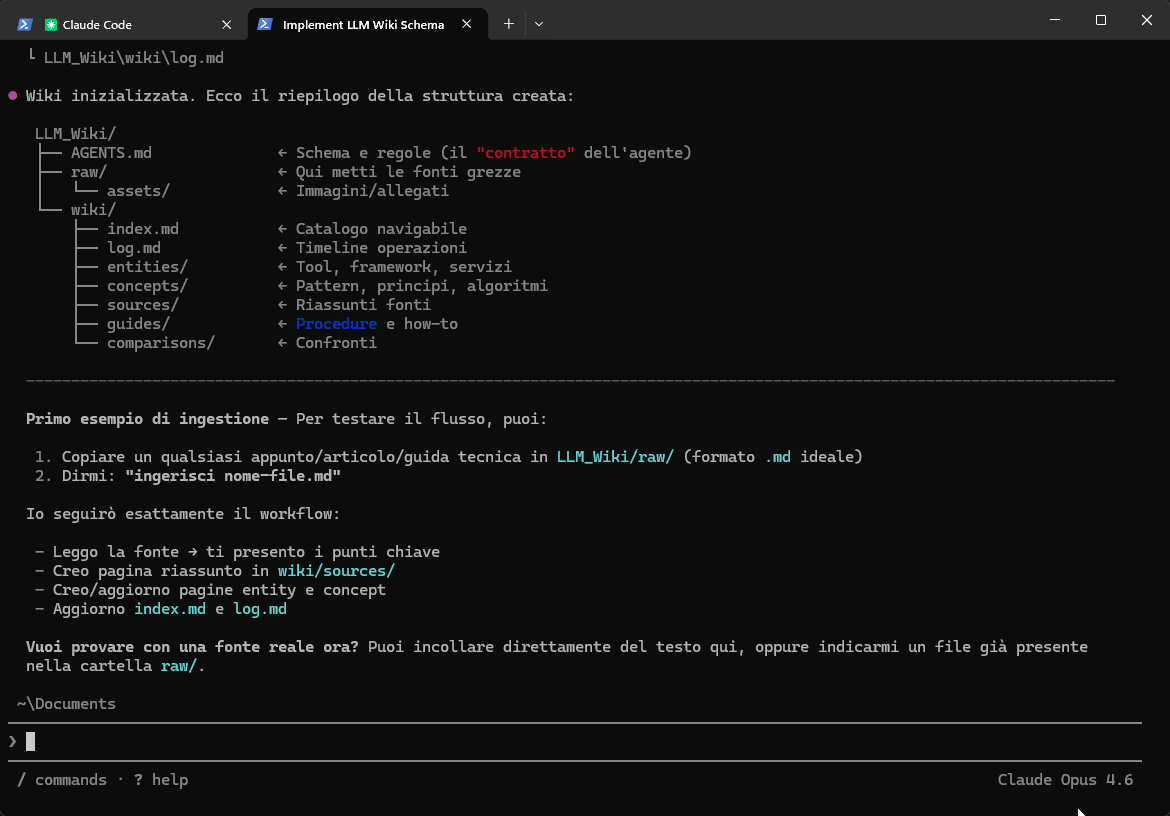
La vera potenza dell'architettura si nota durante l'ingestion delle fonti:
- Caricando un documento, l'LLM non si limita a indicizzarlo, ma crea istantaneamente una rete di pagine interconnesse (concetti, autori, esempi) collegate tramite
[[wikilinks]].
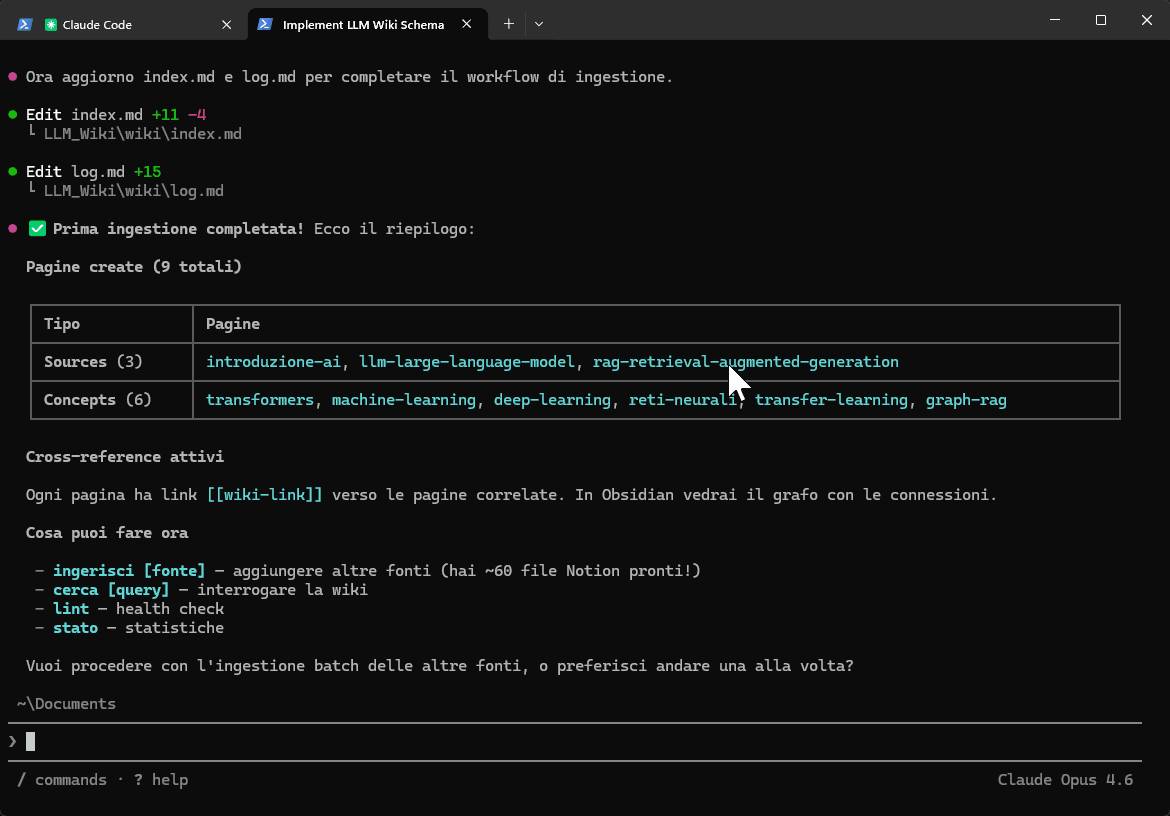
Il coding agent preparerà la struttura:
- Ingestione Ricorsiva: Aggiungendo una seconda fonte, l'IA legge la wiki esistente e aggiorna le pagine. Il sistema diventa più denso perchè vengono rilevate connessioni tra gli autori e rafforzati i riferimenti incrociati in modo autonomo.
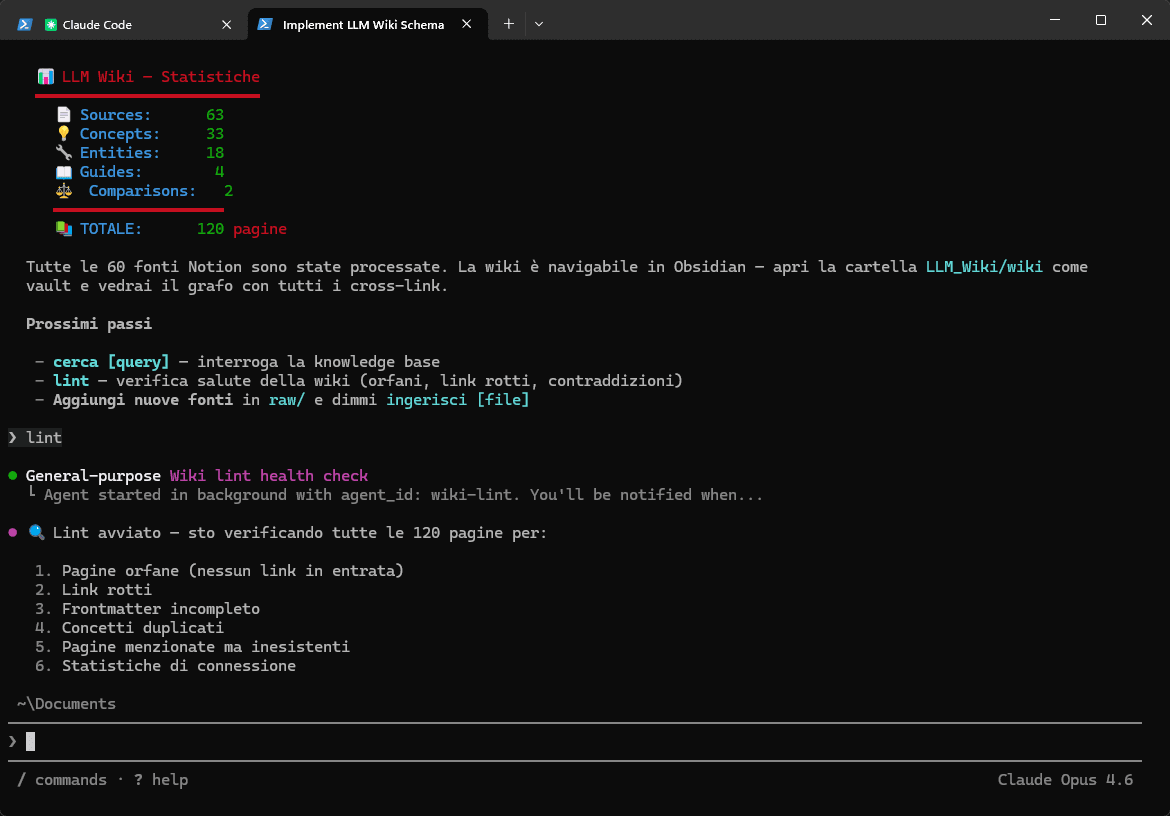
Perchè Obsidian
Obsidian funge da IDE dove l'LLM opera come programmatore e il wiki come codebase.
- Graph View: Permette di visualizzare fisicamente la forma della conoscenza. È possibile identificare a colpo d'occhio i "hub" (pagine centrali) e le "orphans" (pagine isolate che necessitano di manutenzione).
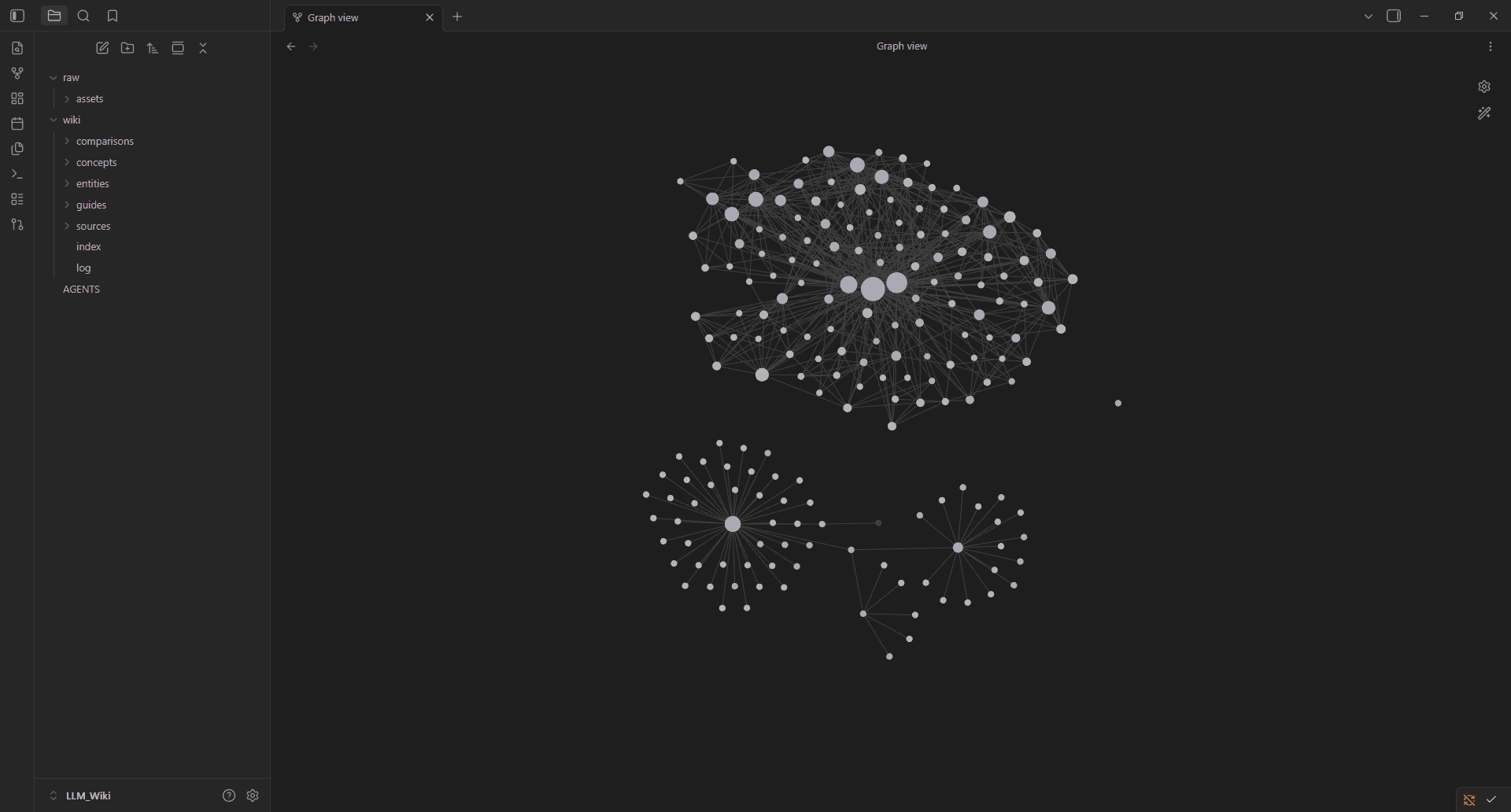
- Ecosistema Estensibile: Plugin come Dataview permettono di generare tabelle dinamiche dai metadati delle note, mentre Marp trasforma il sapere distillato in presentazioni professionali.
Sebbene Obsidian sia la scelta raccomandata per questo workflow grazie alla sua natura local-first e al suo ecosistema di plugin, la forza del pattern risiede proprio nella sua indipendenza tecnologica. Se interpretiamo letteralmente l'intuizione di Karpathy secondo cui "la wiki diventa il codebase e l'LLM il programmatore", utilizzare un editor di codice è la scelta più logica.







