Dentro un modello IA - Funzioni, neuroni artificiali e addestramento
-
Denis Dal Molin
- 14 Mar, 2026
- 15 Mins read
L’Intelligenza Artificiale è entrata stabilmente nel linguaggio quotidiano, ma dietro termini come modelli, training o reti neurali si nascondono concetti ben precisi.
L’IA rappresenta il campo più ampio: l’insieme delle tecniche che consentono a una macchina di eseguire compiti che normalmente richiederebbero capacità cognitive umane. All’interno troviamo il Machine Learning (ML), cioè un insieme di algoritmi che apprendono dai dati e migliorano le proprie prestazioni senza essere esplicitamente programmati per ogni singola regola. Poi c'è il Deep Learning (DL), che utilizza modelli basati su reti neurali artificiali composte da molti livelli, particolarmente efficaci nell’analisi di dati complessi.
Ma cosa è un modello?
Comprendere cosa sia un modello significa guardare sotto il cofano di quella che spesso viene percepita come una "scatola nera", ma che in realtà è un'architettura logica e matematica ben definita.
L'IA non è una creatura magica, è un motore matematico che può essere smontato, studiato e compreso pezzo per pezzo.
Approssimatore di Funzioni
Spogliato del marketing, un modello di intelligenza artificiale può essere visto come un approssimatore di funzioni. Il suo obiettivo è trovare una funzione matematica che trasformi un dato di ingresso (X) nel risultato desiderato (Y).

Partiamo dal caso più semplice: la Regressione Lineare.
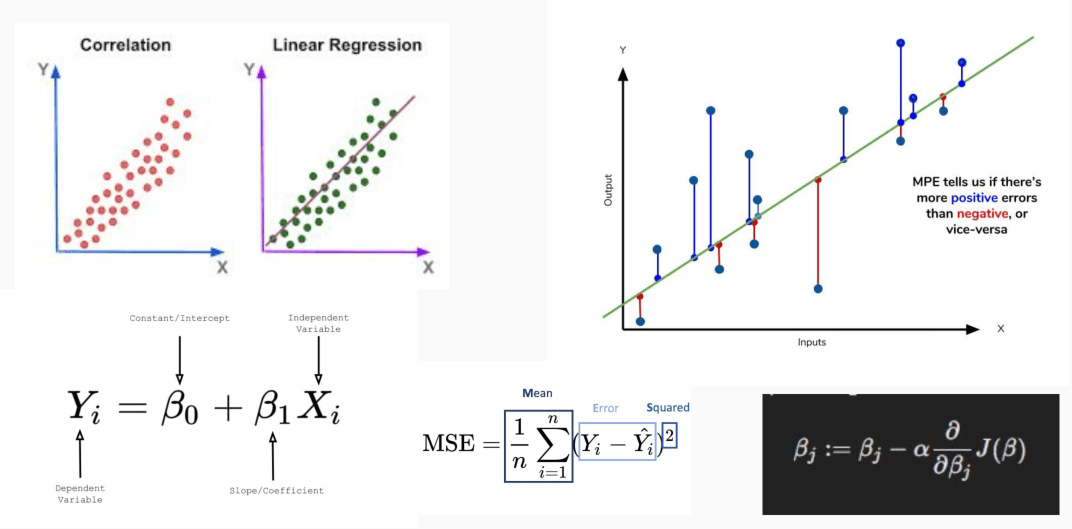
Un regressore lineare è un modello matematico che serve a prevedere un valore numerico (variabile dipendente) a partire da uno o più fattori (variabili indipendenti), assumendo che la relazione tra essi sia approssimativamente lineare.
Immaginiamo di rappresentare su un grafico alcuni dati, ad esempio la relazione tra i metri quadrati di una casa e il suo prezzo. Se i punti mostrano un andamento relativamente regolare possiamo approssimarli con una retta che descrive la relazione tra le due variabili.
Se non avessimo il bias b0, il modello direbbe implicitamente: una casa con 0 metri quadri costa 0**.** Il bias serve proprio a permettere al modello di traslare la funzione verso l'alto o verso il basso per adattarsi meglio ai dati.
- y = variabile dipendente (quello che vogliamo predire);
- x = variabile indipendente (il preditore);
- b0 = la ordinata dell'origine (valore di y quand x = 0), il punto in cui la retta interseca l'asse y;
- b1 = pendenza della retta (misura la variazione di y per ogni unità di variazione di x), indica di quanto varia la variabile dipendente quando la variabile indipendente x aumenta di un'unità. Se la pendenza è positiva, esiste una relazione diretta tra x e y; se è negativa, la relazione è inversa;
- E = errore o residuo che rappresenta la differenza tra tra i valori osservati e quelli previsti.
Quando le variabili sono più di una, non stiamo più stimando una semplice retta ma un iperpiano in uno spazio multidimensionale.
Se la relazione tra le variabili non è lineare, possiamo utilizzare funzioni polinomiali o altre trasformazioni matematiche che permettono di modellare andamenti più complessi.
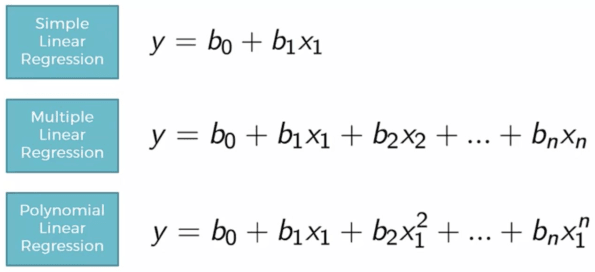
I coefficienti b0,b1,…,bn, rappresentano i parametri del modello, cioè i valori che l’algoritmo deve imparare durante l’addestramento per approssimare al meglio la relazione tra input e output.
Un neurone calcola: y=w1x1+w2x2+...+wnxn+b
- w : pesi delle connessioni
- b : bias del neurone
Il bias introduce un termine costante che consente al neurone di spostare la soglia di attivazione, rendendo il modello più flessibile nell'adattarsi ai dati.
Spesso si tende a usare i termini "correlazione" e "regressione" come sinonimi, ma servono a scopi diversi: la prima descrive un legame esistente, la seconda modella tale legame per fare previsioni sul futuro. Comprendere questa differenza è il primo passo per costruire modelli di IA che non solo "osservano" i dati, ma li utilizzano per generare valore predittivo.
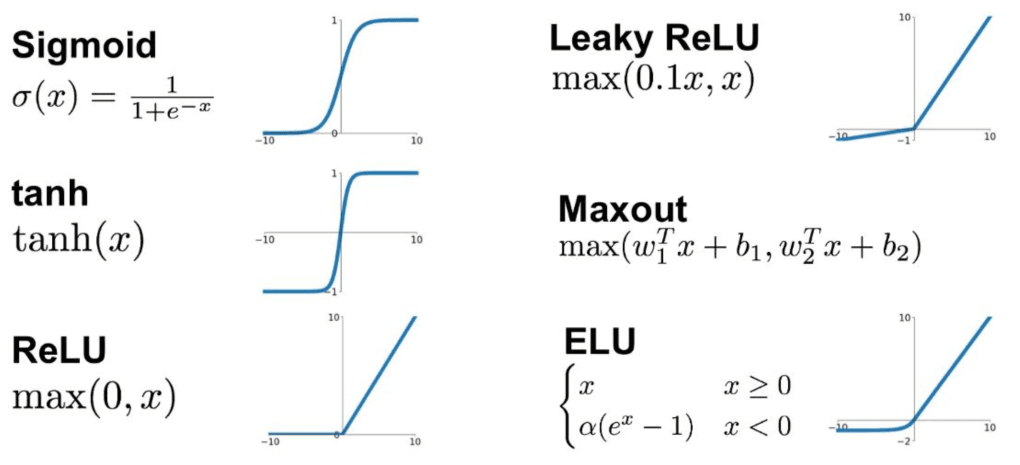
In altri casi non dobbiamo prevedere un valore numerico, ma assegnare una classe (ad esempio stabilire se una mail è spam o no). In questi scenari vengono utilizzate funzioni come la sigmoide, che comprime qualsiasi valore reale in un intervallo compreso tra 0 e 1 e consente di interpretare il risultato come una probabilità.
Prima ancora delle reti neurali, il Machine Learning tradizionale offre anche altri strumenti, tra cui:
- Il K-Nearest Neighbors (KNN) classifica un nuovo dato in base alla somiglianza con i dati più vicini nello spazio delle caratteristiche;
- Il Decision Tree (albero decisionale), invece, costruisce una sequenza gerarchica di regole logiche che suddividono progressivamente i dati fino ad arrivare alla previsione finale.
Anatomia di una Rete Neurale
Quando i dati diventano più complessi e voluminosi, come nel caso di immagini, testo o audio, passiamo alle Reti Neurali Artificiali (ANN).
L’unità fondamentale di queste architetture è il neurone artificiale, spesso chiamato anche perceptron, ispirato in maniera semplificata al funzionamento del neurone biologico.
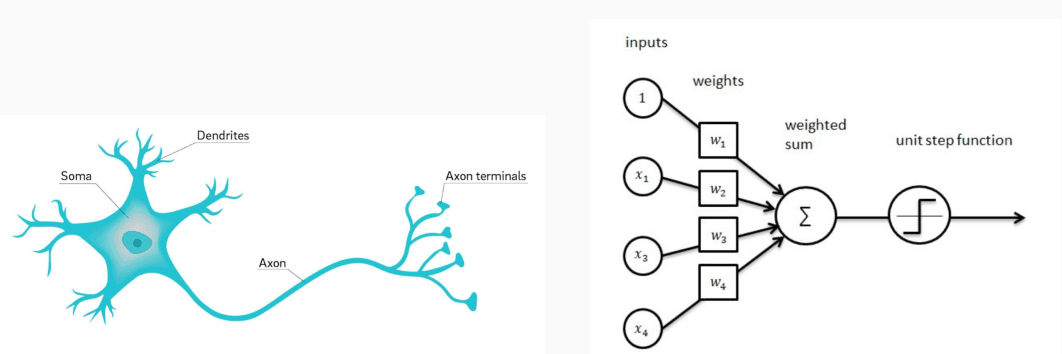
Un neurone artificiale riceve diversi input.
Ad ogni input viene assegnata un'importanza specifica relativa a quel segnale, chiamata Peso (Weight).
Il neurone calcola una somma pesata (funzione di aggregazione) di tutti questi input e applica successivamente una funzione di attivazione, che decide se il neurone deve "accendersi" e trasmettere il segnale in avanti allo strato successivo.
Esistono diverse altre funzioni di attivazione, ognuna con scopi specifici:
- ReLU (Rectified Linear Unit): La più usata negli strati interni delle reti profonde; restituisce 0 se l'input è negativo, altrimenti restituisce l'input stesso ($max(0, x)$);
- Tanh (Tangente Iperbolica): Simile alla sigmoide ma mappa i valori tra -1 e 1;
- Leaky ReLU: Una variante della ReLU che permette un piccolo passaggio di segnale anche per valori negativi, evitando il problema dei "neuroni morti".
Una vera rete neurale è composta da migliaia o milioni di questi nodi, collegati tra loro da "sinapsi" digitali (connessioni) che trasportano i pesi.
L’architettura tipica di una rete si articola in tre componenti principali:
- Input Layer: Il livello di ingresso che riceve i dati grezzi;
- Hidden Layer (Livelli Nascosti): I livelli intermedi, il cuore della rete, dove avviene l'astrazione e l'estrazione delle caratteristiche. Più sono, più la rete è profonda;
- Output Layer: Il livello finale che produce la previsione.
Gli strati interni permettono di dividere il task iniziale in sotto task più semplici aumentano le prestazioni del modello finale.
Una volta compreso come funziona il singolo nodo, il passo successivo è decidere la densità delle connessioni tra i vari strati.
Qui incontriamo due paradigmi fondamentali:
- Modello Dense (Fully Connected): architettura classica in cui ogni neurone di uno strato è collegato a tutti i neuroni dello strato successivo. Questa configurazione è estremamente esigente in termini di memoria e calcolo, poiché ogni peso deve essere memorizzato e aggiornato.
- Modello Sparse (Sparso): molte connessioni vengono rimosse o mantenute a zero. È un approccio ispirato all'efficienza del cervello umano, che attiva solo le aree necessarie per un compito specifico. La sparsità è il segreto dietro i modelli moderni su larga scala (come i Transformer "Mixture of Experts") per ottimizzare le risorse computazionali e permettere a modelli giganteschi di girare con consumi ridotti.
Come si addestra un modello
Per addestrare un modello non basta "scrivere l'algoritmo", si deve seguire un flusso logico:
- Pulizia e preparazione del dataset;
- Calcolo numerico, matrici/tensori;
- Modellazione, definizione dell'architettura.
All'inizio del processo la rete è "stupida", non possiede alcuna conoscenza: i suoi pesi (Parametri) vengono inizializzati in modo casuale.
Il processo di apprendimento avviene attraverso tre passaggi fondamentali:
- Previsione e funzione di Loss: La rete elabora un dato e "tira a indovinare". La previsione viene confrontata con il valore reale. La differenza i due valori viene quantificata tramite una funzione che misura quanto il modello sta sbagliando;
- La Discesa del Gradiente: L'obiettivo è minimizzare la la perdita. Immaginate di essere su una montagna con gli occhi bendati e di voler scendere a valle: l'unico modo è sentire con i piedi la pendenza e muoversi progressivamente verso il basso. Questo è il principio, l'algoritmo matematico indica in quale direzione modificare i parametri per ridurre l'errore;
- Backpropagation: Una volta calcolato l'errore, l'informazione viaggia a ritroso nella rete (dall'output verso l'input). Questo consente di aggiornare i pesi di ogni singola connessione in modo proporzionale al contributo che ciascun parametro ha avuto nell'errore complessivo.
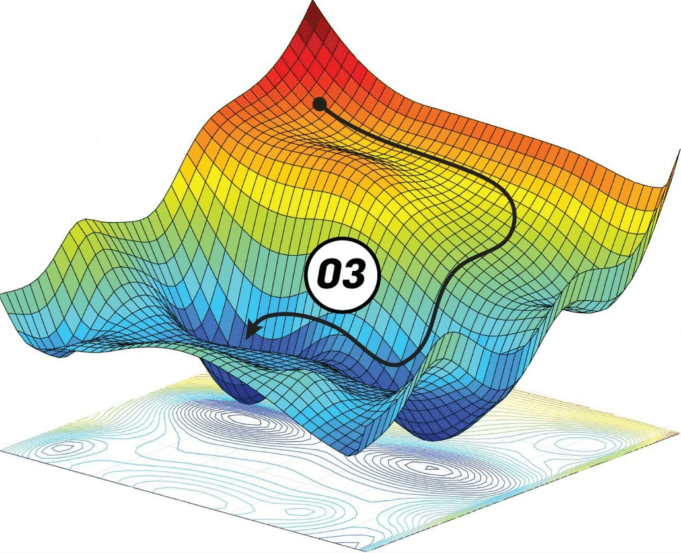
Rappresentazione in 3D dell'errore
Iperparametri
I Pesi vengono imparati automaticamente dal modello durante l'addestramento. Ma esistono gli iperparametri, che sono le "manopole di configurazione" che gli ingegneri impostano prima che inizi il processo.
Tra i più importanti troviamo:
- Learning Rate, che determina la dimensione dei passi nella discesa del gradiente:
- Numero di epoche, cioè quante volte il modello analizza l’intero dataset;
- Architettura della rete, ad esempio numero di layer e numero di neuroni per layer;
- Batch size: Il numero di esempi processati contemporaneamente in ogni passo (dentro la singola epoca). Un batch size maggiore può velocizzare l'addestramento, ma richiede più memoria. Nella pratica si sceglie il batch più grande compatibile con la memoria disponibile nella GPU;
- Ottimizzatore: L'algoritmo che regola i pesi del modello. Adam è uno degli ottimizzatori più usati poiché combina i vantaggi della discesa del gradiente stocastica con adattamenti del tasso di apprendimento;
- Funzione di perdita: Una funzione che misura quanto siano sbagliate le previsioni del modello, calcola l’errore. Per compiti di classificazione si usano funzioni come la cross-entropy loss, mentre per la regressione si può usare la mean squared error.
Ad esempio potremmo progettare una rete con 3 hidden layer da 16 neuroni ciascuno.
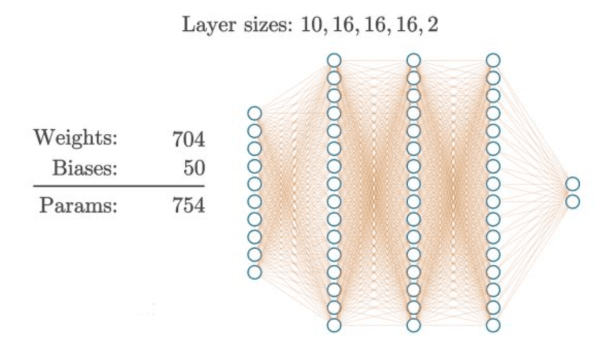
Come facciamo a sapere quale è la configurazione migliore? Per individuare la configurazione più efficace si utilizzano tecniche di hyperparameter tuning, come la grid search, che addestra il modello molte volte testando diverse combinazioni di parametri.
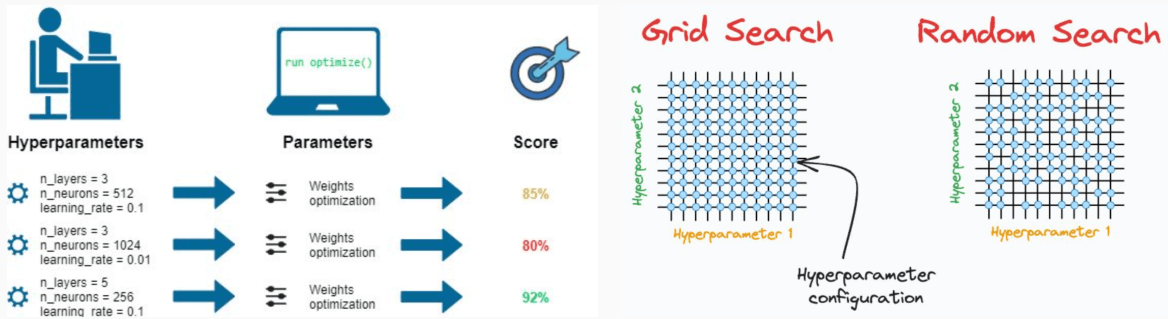
Questo è uno dei motivi per cui l’addestramento di modelli richiede una notevole quantità di risorse computazionali: miliardi di operazioni matematiche vengono eseguite su molte varianti dello stesso modello, spesso per giorni o settimane.
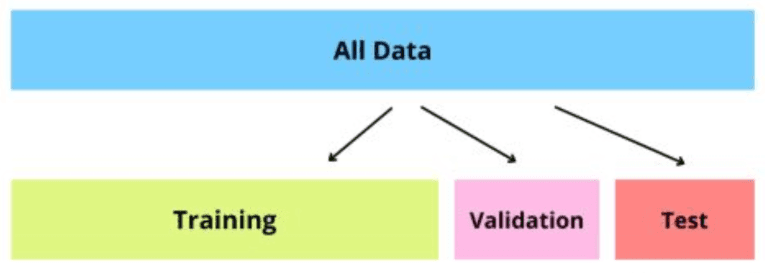
Gestione dei dati
Tutto questo non serve a nulla se non gestiamo bene i dati attraverso tre fasi: Model Training, Model Selection e Model Assessment.
Un modello matematico, per quanto sofisticato, non ha senso critico. Se lo alimentiamo con dati sporchi, distorti o irrilevanti, le sue previsioni saranno altrettanto inutili.
Questo principio universale è noto come Garbage In, Garbage Out (GIGO). Per questo motivo, i Data Scientist eseguono un profondo Feature Engineering, selezionando e trasformando le colonne di dati grezzi per far emergere i veri pattern matematici, scartando rumore di fondo inutile.
Il formato del dataset dipende dal tipo di compito e dal modello che stai utilizzando. I dataset possono avere diverse estensioni e strutture, ma generalmente i formati più comuni sono:
- CSV (Comma Separated Values): Un formato tabellare dove ogni riga è un esempio e ogni colonna rappresenta una caratteristica (ad esempio, una recensione e la sua etichetta di sentiment);
- JSON (JavaScript Object Notation): Molto usato per strutturare dati complessi, ad esempio domande e risposte;
- TSV (Tab-Separated Values): Simile al CSV, ma con separatori di tabulazioni;
- Parquet: Un formato binario colonnare che è molto usato per dati di grandi dimensioni e per una maggiore efficienza di lettura/scrittura.
Il dataset iniziale viene tipicamente diviso in due parti:
- Training set (circa 80%)
- Test set (circa 20%)
Il test set viene mantenuto separato e non viene mai utilizzato durante l’addestramento.
Il training set viene poi ulteriormente suddiviso per ottenere anche un validation set, utilizzato per valutare il modello durante il training.
Durante l’addestramento si osservano costantemente due indicatori principali:
- la loss sul training set
- la loss sul validation set
Nella pratica è molto comune applicare una fase di feature scaling prima dell'addestramento. Questo perché le variabili possono avere ordini di grandezza molto diversi tra loro. Senza una normalizzazione, alcune feature potrebbero dominare il processo di ottimizzazione rendendo la discesa del gradiente instabile o molto lenta. Tecniche come la standardizzazione (z-score) o il min-max scaling permettono di riportare le variabili su scale comparabili, facilitando la convergenza.
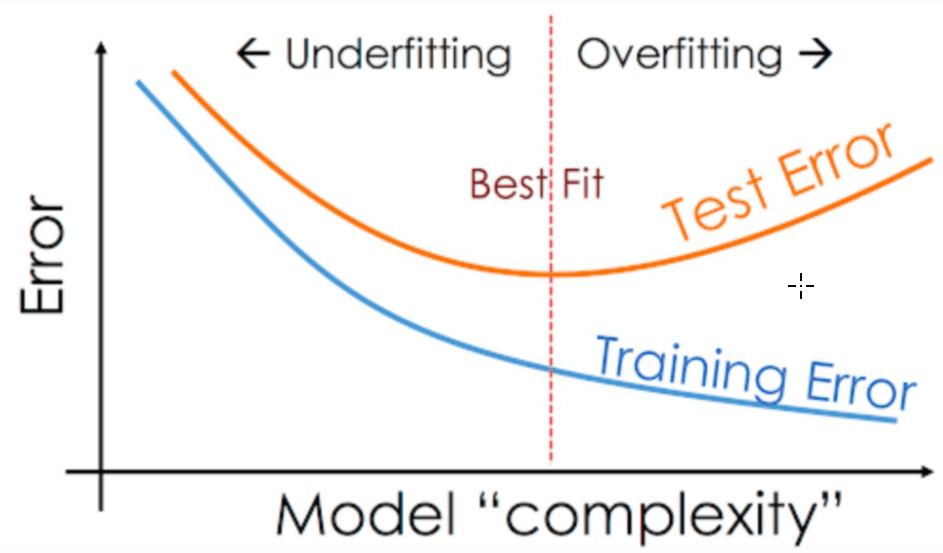
La convergenza avviene quando la funzione di perdita non diminuisce più in modo significativo. L'addestramento potrebbe quindi essere interrotto perché il modello ha trovato una soluzione ottimale.
Se il modello viene addestrato troppo a lungo, può verificarsi un fenomeno chiamato overfitting: il modello impara perfettamente ("a memoria") i dati di training ma perde la capacità di generalizzare su dati nuovi.
Per evitare l'overfitting, vengono utilizzati metodi come:
- Regularization: Aggiungere un termine alla funzione di perdita che penalizza i pesi troppo grandi (ad esempio L1 o L2 regularization);
- Early Stopping: Monitorare la prestazione del modello sui dati di validazione e fermare l'addestramento quando le prestazioni sui dati di validazione cominciano a peggiorare (indicando overfitting).
early_stopping = EarlyStopping(
monitor='val_accuracy',
patience=5,
restore_best_weights=True
)
Early stopping configurato tramite un callback di Keras
La "patience" (pazienza) indica un numero di epoche consecutive che il modello può sopportare senza mostrare miglioramenti sulla metrica monitorata (in questo caso val_accuracy) prima che il training venga interrotto.
Il fenomeno opposto è l’underfitting, che si verifica quando il modello non riesce a catturare sufficientemente la struttura dei dati.
Identificata la combinazione migliore di iperparametri, si procede alla valutazione finale utilizzando il test set, che rappresenta una simulazione realistica delle prestazioni del modello su dati mai visti prima. Se il modello raggiunge, ad esempio, un’accuratezza dell’85%, non è metodologicamente corretto modificare il modello e ripetere il test sullo stesso dataset.
Perché? Sarebbe equivalente a far sostenere ad uno studente lo stesso esame più volte finché non ottiene il voto desiderato: il risultato migliorerebbe in modo artificiale, ma non rifletterebbe le reali capacità del modello. Se l'accuratezza finale non ci soddisfa la conclusione più pragmatica è spesso anche la più corretta: il modello ha probabilmente raggiunto il limite informativo dei dati disponibili, servono più dati.
Cosa è un tensore?
Un tensore è un contenitore di numeri, come l'evoluzione geometrica di una lista:
Scalare (0D): Un singolo numero (es. $5$).
Vettore (1D): Una lista di numeri (es. le caratteristiche di una casa: $[mq, \text{stanze}, \text{prezzo}]$).
Matrice (2D): Una tabella di numeri (es. un foglio Excel).
Tensore (3D o superiore): Una "pila" di matrici.
- Un'immagine a colori è un tensore 3D: ha altezza, larghezza e 3 canali di colore (RGB).
In una rete neurale, tutto, che sia un testo, un suono o un'immagine, viene trasformato in tensori. Questi numeri "scorrono" attraverso le funzioni della rete, venendo moltiplicati per dei pesi per generare una previsione.
Librerie
Prima ancora di scrivere codice, ci serve un'officina. Anaconda non è una libreria, ma una "distribuzione" e un gestore di ambienti. Mentre i classici ambienti virtuali di Python si limitano a isolare i pacchetti software, nel Machine Learning abbiamo a che fare con driver di sistema e librerie scritte in C/C++ (come CUDA). È la soluzione chiavi in mano più sicura per iniziare, anche se di recente gli sviluppatori più esperti stanno esplorando alternative iper-veloci e minimaliste scritte in Rust, come uv.
Possiamo dividere gli strumenti in tre categorie principali:
Le fondamenta (Dati e Matematica)
NumPy: È la libreria base per il calcolo scientifico. Gestisce array multidimensionali. In IA, tutto (immagini, testi, suoni) viene convertito in numeri dentro array NumPy.
- calcolo tensoriale (trasformazione dati grezzi in input numerici).
Pandas: Immaginalo come "Excel sotto steroidi" per Python. Si usa per caricare file CSV/JSON, pulire i dati, gestire valori mancanti e analizzare tabelle (DataFrame).
- pulizia dei dati e suddivisione.
Scikit-learn (sklearn): È il coltellino svizzero del Machine Learning tradizionale (non neurale). Si usa per preparare i dati (scaling, normalizzazione) e per algoritmi classici come regressioni o foreste decisionali.
- pulizia dei dati e suddivisione.
Deep Learning engines (Tensori e gradienti) - Backpropagation, librerie che gestiscono il calcolo automatico, gestiscono la derivazione automatica necessaria per aggiornare i pesi.
PyTorch: Creato da Meta, è oggi lo standard nella ricerca e sempre più in produzione. È molto "Pythonic" e flessibile. Se vuoi capire bene come fluiscono i dati, PyTorch è eccellente.
- usato molto anche per scaricare modelli pre-addestrati e adattarli.
TensorFlow: Creato da Google, è un ecosistema massiccio. Molto forte per il deployment su larga scala e in ambienti industriali (TensorFlow Extended, Lite).
Interfacce di alto livello (Modelli e astrazione)
- Keras: Originariamente una libreria indipendente, oggi è l'interfaccia ufficiale di TensorFlow. Serve a scrivere codice in modo semplice e rapido. Invece di scrivere 50 righe di matematica, scrivi
model.add(Dense(64))nascondendo la complessità matematica dei gradienti, è l'ideale per i principianti. - Hugging Face Transformers: La porta d'accesso ai modelli moderni, permette di configurare e addestrare modelli pre-addestrati, si usa per il fine-tuning. Supporta nativamente sia PyTorch che TensorFlow.
- Keras: Originariamente una libreria indipendente, oggi è l'interfaccia ufficiale di TensorFlow. Serve a scrivere codice in modo semplice e rapido. Invece di scrivere 50 righe di matematica, scrivi
Orchestrazione e Agentic AI (il cervello del sistema)
- LangChain/LangGraph: Non servono per creare i pesi della rete ma a collegare il modello Keras/Pytorch a strumenti esterni (database, ricerche web, etc..) e a gestire cicli di ragionamento (chain of thought).
- Pydantic: Fondamentale per la validazione dei dati, assicura che l'output del modello sia strutturato correttamente (es. un JSON) prima di passarlo a un altro software.
Dalla teoria al codice
Oggi, un ambiente di lavoro standard per un data scientist è il Jupyter Notebook, spesso ospitato su piattaforme cloud come Google Colab. Colab ci permette di "noleggiare" gratuitamente le potentissime GPU di Google.
Strumenti e dati
Prima di costruire il modello, dobbiamo importare le librerie come Pandas, Scikit-Learn e TensorFlow/Keras e scaricare il dataset.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
# Caricamento del dataset Adult dal repository UCI
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
columns = ["age", "workclass", "fnlwgt", "education", "education-num",
"marital-status", "occupation", "relationship", "race", "sex",
"capital-gain", "capital-loss", "hours-per-week", "native-country", "income"]
df = pd.read_csv(url, header=None, names=columns, skipinitialspace=True)
In questo esempio, usiamo un dataset famoso chiamato "Adult", il cui obiettivo è prevedere se una persona guadagna più o meno di 50.000 dollari l'anno in base a caratteristiche come età, istruzione e occupazione.

Pulizia e preparazione
Le reti neurali non capiscono parole come "Laureato" o "Sposato", ma solo numeri.
In questa fase eliminiamo i dati mancanti e traduciamo tutto in formato matematico. Le colonne numeriche (come l'età) vengono "normalizzate" per avere tutte la stessa scala, mentre le categorie testuali vengono trasformate in matrici di zeri e uni (OneHotEncoder).
Se i dati non vengono scalati l'algoritmo di ottimizzazione (come il Gradient Descent) percepirà le variabili come valori assoluti più come molto più importanti rispetto a quelle con valori più bassi, semplicemente perche i loro numeri sono più grandi. Matematicamente, questo crea una funzione di costo (Loss Function) deformata: invece di essere un cerchio perfetto (una ciotola), diventa un'ellisse stretta e lunghissima.
# Pulizia valori mancanti
df = df.replace('?', np.nan).dropna()
# Separazione tra input (X) e output desiderato (y)
X = df.drop("income", axis=1)
y = df["income"].apply(lambda x: 1 if x.strip() == ">50K" else 0)
# Definizione e trasformazione delle variabili (Numeriche e Categoriche)
numeric_features = ["age", "fnlwgt", "education-num", "capital-gain", "capital-loss", "hours-per-week"]
categorical_features = [col for col in X.columns if col not in numeric_features]
numeric_transformer = Pipeline(steps=[('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# Applica la trasformazione e dividi i dati
X_processed = preprocessor.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_processed, y, test_size=0.2, random_state=42)
input_dim = X_train.shape[1]
Infine, applichiamo la regola d'oro: dividiamo i dati in Training Set (per studiare) e Test Set (per l'esame finale, che chiudiamo in cassaforte contest_size=0.2).
Costruzione della rete neurale e addestramento
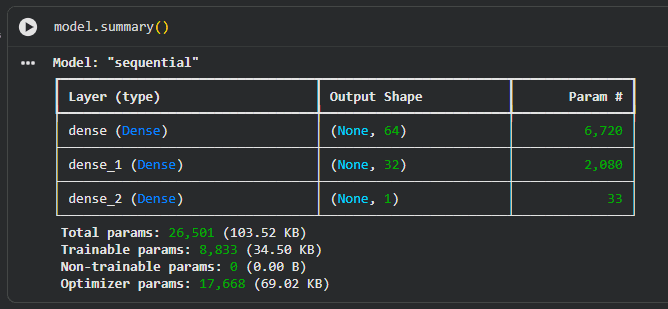
Creiamo un modello sequenziale con tre strati: un primo Hidden Layer da 64 neuroni, un secondo da 32 neuroni, e un Output Layer da 1 singolo neurone (che userà la funzione Sigmoide per dirci la probabilità tra 0 e 1).
Successivamente "compiliamo" il modello dicendogli come calcolare l'errore (loss='binary_crossentropy') e come aggiornare i pesi (optimizer=Adam).
model = Sequential()
model.add(Dense(64, input_dim=input_dim, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# Compilazione e Addestramento
model.compile(loss='binary_crossentropy', optimizer=Adam(), metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=10, batch_size=256, validation_split=0.2)
L'approccio Sequential segue una logica lineare in cui ogni strato ha esattamente un tensore di input e uno di output, ogni layer segue l'altro in modo rigido.
Nella realtà, però, i problemi che affrontiamo sono spesso più complessi e richiedono una flessibilità maggiore:
- Multi-input: per ntegrare contemporaneamente sorgenti diverse, come dati testuali e strutturati;
- Skip connections: connessioni che saltano alcuni strati per evitare la perdita di informazioni o rami che si dividono e ricongiungono;
- Output multipli: per costruire un unico modello che esegue compiti diversi nello stesso momento, come una classificazione e una regressione.
La Functional API risolve questi limiti trattando ogni strato come una vera e propria funzione applicata a un tensore.
In questo paradigma, l'input viene definito esplicitamente, permettendo di mappare flussi di dati complessi e non lineari, trasformando la rete da una semplice "lista" a un vero e grafo di operazioni interconnesse.
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
# 1. Definiamo esplicitamente il tensore di input
input_tensor = Input(shape=(input_dim,))
# 2. Ogni strato è una funzione chiamata sull'output del precedente
x = Dense(64, activation='relu')(input_tensor)
x = Dense(32, activation='relu')(x)
# 3. Definiamo l'output finale
output_tensor = Dense(1, activation='sigmoid')(x)
# 4. Creiamo l'istanza finale del modello
model_functional = Model(inputs=input_tensor, outputs=output_tensor)
Lo stesso modello di prima, riscritto con approccio Functional
Infine avviamo l'addestramento con model.fit, definendo gli iperparametri: 10 epoche di studio, pacchetti da 256 righe alla volta, usando il 20% dei dati di training come Validation Set.
Possiamo chiedere a Python di disegnarci la vera e propria topologia della rete, esportandola in un'immagine.
from keras_visualizer import visualizer
from IPython.display import Image
# Genera un'immagine (grafo) della topologia della nostra Rete Neurale
visualizer(model, file_format='png', view=True)
# Mostra l'immagine direttamente all'interno di Google Colab
Image('graph.png')
In questo modo verifichiamo visivamente che il numero di neuroni e di Hidden Layer sia esattamente quello che avevamo progettato.
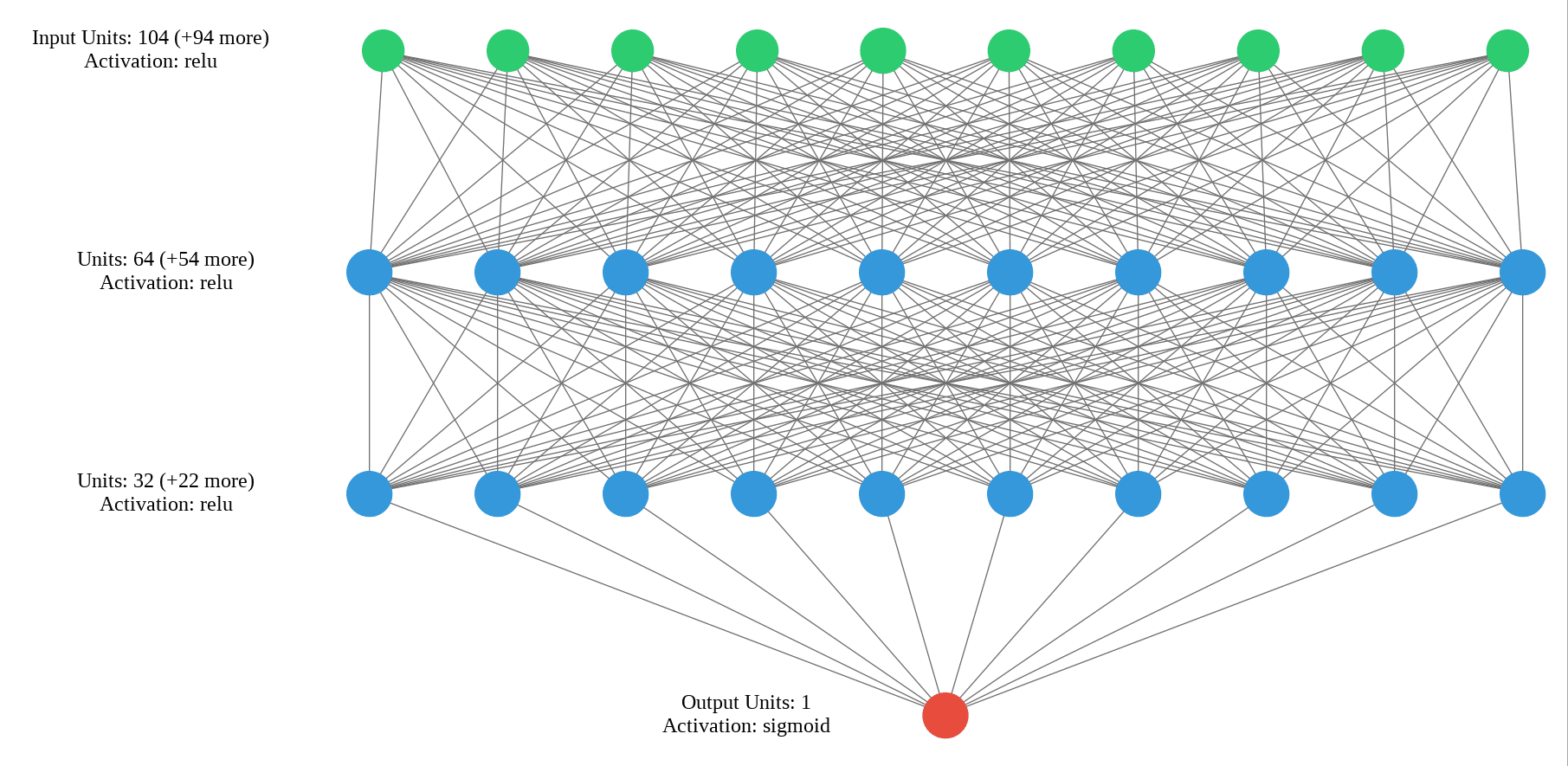
Questa è un'architettura feed-forward, ogni neurone di un livello è rigidamente collegato a tutti i neuroni del livello precedente. Quando elabora i dati di una persona, li "guarda" tutti insieme, in blocco, pesandoli simultaneamente.
I modelli linguistici moderni non leggono le informazioni in blocchi statici, ma fanno uso di architetture Transformer. Queste reti utilizzano meccanismi chiamati Attention Head, che permettono alla macchina di scansionare lunghe sequenze di dati (come le parole di un intero documento) capendo dinamicamente a quale parte del testo prestare attenzione in base al contesto.
Monitorare il processo
Mentre il modello macina dati, vogliamo essere sicuri che stia imparando davvero e non solo memorizzando.
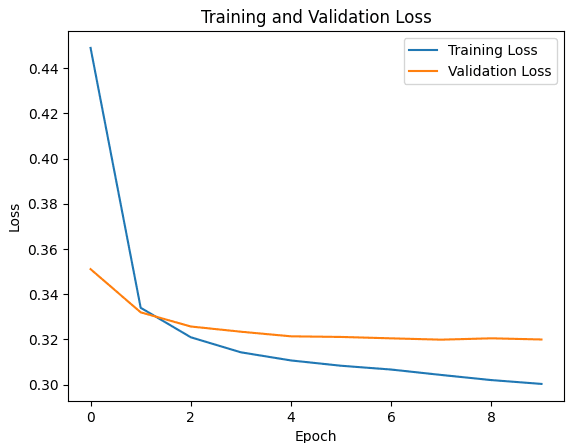
Chiediamo a Python di disegnarci un grafico che metta a confronto l'errore sui dati che il modello sta studiando (Training Loss) e l'errore sui dati di controllo (Validation Loss).
import matplotlib.pyplot as plt
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
Se entrambe le curve scendono, stiamo andando nella giusta direzione.
Test finale
Il modello è pronto, dobbiamo valutare le sue prestazioni reali.
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test loss: {loss:.4f}")
print(f"Test accuracy: {accuracy:.4f}")
Il modello addestrato viene "congelato" esportato come file e caricato su un server. A quel punto i team di sviluppo gli costruiscono intorno un'API.

Dal laboratorio al mondo reale
In questo articolo abbiamo esplorato l'anatomia di una rete neurale costruendola e addestrandola from scratch. A scopo didattico, è l'unico modo per comprendere davvero la meccanica dei pesi, delle loss function e dell'ottimizzazione. Nel panorama aziendale odierno però le regole si sono evolute, nessuno addestra reti da miliardi di parametri partendo da zero; i costi di calcolo sarebbero insostenibili. Oggi domina il Transfer Learning (Fine-Tuning): si prende un "modello foundational" gigantesco, già addestrato dalle Big Tech su gran parte della conoscenza umana, e lo si specializza.
In produzione, il modello deve essere isolato, portabile e replicabile. Normalmente si utilizza Kubernetes (K8s) come orchestratore per la gestione del ciclo di vita, occupandosi di far salire nuove istanze del modello se il traffico aumenta (scaling) e di riavviarle in caso di crash (self-healing).
Per garantirne la salute, implementiamo un sistema di monitoraggio basato su Prometheus per la raccolta delle metriche e Grafana per la loro visualizzazione. Oltre ai dati infrastrutturali (come latenza, consumo di GPU e RAM), è fondamentale monitorare metriche specifiche del modello: la Prediction Drift (per capire se i dati reali stanno cambiando rispetto a quelli di training) e la Confidence Score delle risposte.
La sicurezza in un sistema IA moderno non riguarda solo le reti, ma il contenuto stesso. Implementiamo i Guardrails (safety patterns): filtri di sicurezza che validano l'input dell'utente e l'output del modello per prevenire allucinazioni, contenuti tossici o tentativi di "jailbreak".
Il passaggio finale riguarda la responsabilità. Progettare un'IA etica significa integrare la sicurezza sin dal design: filtri logici che validano input e output per prevenire pregiudizi (bias), contenuti non sicuri o violazioni della privacy. Adottare un approccio responsabile significa garantire che il sistema sia interpretabile e che rispetti rigorosi standard di sicurezza limitando l'accesso del modello solo ai dati strettamente necessari.
L'obiettivo non è solo creare un sistema potente ma costruire una tecnologia trasparente e affidabile che metta la sicurezza dell'utente e l'integrità del dato al centro di ogni decisione.
Prova una rete neurale da browser
Se vuoi vedere visivamente come una rete neurale impara a separare i dati, puoi usare TensorFlow Playground, uno strumento interattivo che permette di modificare:
- numero di layer
- numero di neuroni
- funzione di attivazione
- learning rate
e osservare in tempo reale come cambia la frontiera decisionale del modello.